

Java后端线上问题排查常用命令收藏
发布于 2021-05-08 10:59 ,所属分类:JAVA工程师开发学习资料
点击上方蓝色“后端面试那些事儿”,选择“设为星标”
学最好的别人,做最好的自己
来源:http://r6d.cn/b97q7
内存瓶颈
free
free是查看内存使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
free -h -s 3表示每隔三秒输出一次内存情况,命令如下
[1014154@cc69dd4c5-4tdb5~]$free
totalusedfreesharedbuff/cacheavailable
Mem:119623656430522204561136443137603096007270574408
Swap:000
[1014154@cc69dd4c5-4tdb5~]$free-h-s3
totalusedfreesharedbuff/cacheavailable
Mem:114G41G43G4.1G29G67G
Swap:0B0B0B
totalusedfreesharedbuff/cacheavailable
Mem:114G41G43G4.1G29G67G
Swap:0B0B0B
Mem:是内存的使用情况。Swap:是交换空间的使用情况。total:系统总的可用物理内存和交换空间大小。used:已经被使用的物理内存和交换空间。free:还有多少物理内存和交换空间可用使用,是真正尚未被使用的物理内存数量。shared:被共享使用的物理内存大小。buff/cache:被 buffer(缓冲区) 和 cache(缓存) 使用的物理内存大小。available:还可以被应用程序使用的物理内存大小,它是从应用程序的角度看到的可用内存数量,available ≈ free + buffer + cache。
交换空间(swap space)
swap space 是磁盘上的一块区域,当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
vmstat(推荐)
vmstat(VirtualMeomoryStatistics,虚拟内存统计)是Linux中监控内存的常用工具,可对操作系统的虚拟内存、进程、CPU等的整体情况进行监视,推荐使用。
vmstat 5 3表示每隔5秒统计一次,一共统计三次。
[1014154@cc69dd4c5-4tdb5~]$vmstat53
procs-----------memory-------------swap-------io-----system--------cpu-----
rbswpdfreebuffcachesisobiboincsussyidwast
80045453212374768307637280014991111107801
100045489232374768307633600021275951189790813117501
60045452908374768307651480003996899249207312107801
procs
r:表示运行和等待CPU时间片的进程数(就是说多少个进程真的分配到CPU),这个值如果长期大于系统CPU个数,说明CPU不足,需要增加CPU。b:表示在等待资源的进程数,比如正在等待I/O或者内存交换等。
memory
swpd:表示切换到内存交换区的内存大小,即虚拟内存已使用的大小(单位KB),如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。free:表示当前空闲的物理内存。buff:表示缓冲大小,一般对块设备的读写才需要缓冲Cache:表示缓存大小,一般作为文件系统进行缓冲,频繁访问的文件都会被缓存,如果cache值非常大说明缓存文件比较多,如果此时io中的bi比较小,说明文件系统效率比较好。
swap
si:表示数据由磁盘读入内存;通俗的讲就是每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。so:表示由内存写入磁盘,也就是由内存交换区进入内存的数据大小。
!!注意:一般情况下si、so的值都为0,如果si、so的值长期不为0,则说明系统内存不足,需要增加系统内存
io
bi:表示由块设备读入数据的总量,即读磁盘,单位kb/s bo:表示写到块设备数据的总量,即写磁盘,单位kb/s
!!注意:如果bi+bo的值过大,且wa值较大,则表示系统磁盘IO瓶颈。
system
in:表示某一时间间隔内观测到的每秒设备终端数。cs:表示每秒产生的上下文切换次数,这个值要越小越好,太大了,要考虑调低线程或者进程的数目。例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
!!注意:这两个值越大,则由内核消耗的CPU就越多。
CPU
us:表示用户进程消耗的CPU时间百分比,us值越高,说明用户进程消耗CPU时间越多,如果长期大于50%,则需要考虑优化程序或者算法。sy:表示系统内核进程消耗的CPU时间百分比,一般来说us+sy应该小于80%,如果大于80%,说明可能存在CPU瓶颈。id:表示CPU处在空间状态的时间百分比。wa:表示IP等待所占用的CPU时间百分比,wa值越高,说明I/O等待越严重,根据经验wa的参考值为20%,如果超过20%,说明I/O等待严重,引起I/O等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者监控器的贷款瓶颈(主要是块操作)造成的。
sar
sar和free类似sar -r 3每隔三秒输出一次内存信息:
[root@localhost~]#sar-r3
Linux3.10.0-1062.el7.x86_64(localhost.localdomain)2020年04月28日_x86_64_(2CPU)
15时40分10秒kbmemfreekbmemused%memusedkbbufferskbcachedkbcommit%commitkbactivekbinactkbdirty
15时40分13秒106800131496092.4921445732484110864116.8256366449888836
15时40分16秒106816131494492.4921445732484110864116.8256366849888836
15时40分19秒106816131494492.4921445732484110864116.8256366849888836
CPU瓶颈
查看机器cpu核数
CPU总核数=物理CPU个数*每颗物理CPU的核数
总逻辑CPU数=物理CPU个数*每颗物理CPU的核数*超线程数
查看CPU信息(型号)
[1014154@cc69dd4c5-4tdb5~]$cat/proc/cpuinfo|grepname|cut-f2-d:|uniq-c
32Intel(R)Xeon(R)CPUE5-2650v4@2.20GHz
查看物理CPU个数
[1014154@cc69dd4c5-4tdb5~]$cat/proc/cpuinfo|grep"physicalid"|sort|uniq|wc-l
16
查看每个物理CPU中core的个数(即核数)
[1014154@cc69dd4c5-4tdb5~]$cat/proc/cpuinfo|grep"cpucores"|uniq
cpucores:2
查看逻辑CPU的个数
[1014154@cc69dd4c5-4tdb5~]$cat/proc/cpuinfo|grep"processor"|wc-l
32
top
在Linux内核的操作系统中,进程是根据虚拟运行时间(由进程优先级、nice值加上实际占用的CPU时间进行动态计算得出)进行动态调度的。在执行进程时,需要从用户态转换到内核态,用户空间不能直接操作内核空间的函数。通常要利用系统调用来完成进程调度,而用户空间到内核空间的转换通常是通过软中断来完成的。例如要进行磁盘操作,用户态需要通过系统调用内核的磁盘操作指令,所以CPU消耗的时间被切分成用户态CPU消耗、系统(内核) CPU 消耗,以及磁盘操作 CPU 消耗。执行进程时,需要经过一系列的操作,进程首先在用户态执行,在执行过程中会进行进程优先级的调整(nice),通过系统调用到内核,再通过内核调用,硬中断、软中断,让硬件执行任务。执行完成之后,再从内核态返回给系统调用,最后系统调用将结果返回给用户态的进程。
top可以查看CPU总体消耗,包括分项消耗,如User,System,Idle,nice等。Shift + H显示java线程;Shift + M按照内存使用排序;Shift + P按照CPU使用时间(使用率)排序;Shift + T按照CPU累积使用时间排序;多核CPU,进入top视图1,可以看到各各CPU的负载情况。
top-15:24:11up8days,7:52,1user,loadaverage:5.73,6.85,7.33
Tasks:17total,1running,16sleeping,0stopped,0zombie
%Cpu(s):13.9us,9.2sy,0.0ni,76.1id,0.1wa,0.0hi,0.1si,0.7st
KiBMem:11962365+total,50086832free,38312808used,31224016buff/cache
KiBSwap:0total,0free,0used.75402760availMem
PIDUSERPRNIVIRTRESSHRS%CPU%MEMTIME+COMMAND
300ymmapp20017.242g1.234g14732S2.31.19:40.38java
1root2001537619881392S0.00.00:00.06sh
11root200120660114161132S0.00.00:04.94python
54root2008532822401652S0.00.00:00.00su
55ymmapp2001743218081232S0.00.00:00.00bash
56ymmapp2001755621561460S0.00.00:00.03control.sh
57ymmapp20011880740576S0.00.00:00.00tee
115ymmapp2001755621121464S0.00.00:00.02control_new_war
133root20010603242403160S0.00.00:00.03sshd
134ymmapp2001708068723180S0.00.00:01.82ops-updater
147ymmapp2001795626361544S0.00.00:00.07control.sh
6538ymmapp200115656105323408S0.00.00:00.46beidou-agent
6785ymmapp2002572996225122788S0.00.00:03.44gatherinfo4dock
29241root20014214857124340S0.00.00:00.04sshd
2924310141542001421482296924S0.00.00:00.00sshd
2924410141542001520820201640S0.00.00:00.00bash
3264110141542005736420201480R0.00.00:00.00top
第一行:15:24:11 up 8 days, 7:52, 1 user, load average: 5.73, 6.85, 7.33:15:24:11 系统时间,up 8 days 运行时间,1 user 当前登录用户数,load average 负载均衡情况,分别表示1分钟,5分钟,15分钟负载情况。
第二行:Tasks: 17 total, 1 running, 16 sleeping, 0 stopped, 0 zombie:总进程数17,运行数1,休眠 16,停止0,僵尸进程0。
第三行:%Cpu(s): 13.9 us, 9.2 sy, 0.0 ni, 76.1 id, 0.1 wa, 0.0 hi, 0.1 si, 0.7 st:用户空间CPU占比13.9%,内核空间CPU占比9.2%,改变过优先级的进程CPU占比0%,空闲CPU占比76.1,IO等待占用CPU占比0.1%,硬中断占用CPU占比0%,软中断占用CPU占比0.1%,当前VM中的cpu 时钟被虚拟化偷走的比例0.7%。
第四和第五行表示内存和swap区域的使用情况。
第七行表示:
PID: 进程idUSER:进程所有者PR:进程优先级NI:nice值。负值表示高优先级,正值表示低优先级VIRT:虚拟内存,进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RESRES:常驻内存,进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATASHR:共享内存,共享内存大小,单位kbS:进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程%CPU:上次更新到现在的CPU时间占用百分比%MEM:进程使用的物理内存百分比TIME+:进程使用的CPU时间总计,单位1/100秒COMMAND:进程名称(命令名/命令行)
计算在cpu load里面的uninterruptedsleep的任务数量
top-b-n1|awk'{if(NR<=7)print;elseif($8=="D"){print;count++}}END{print"TotalstatusD:"count}'
[root@localhost~]#top-b-n1|awk'{if(NR<=7)print;elseif($8=="D"){print;count++}}END{print"TotalstatusD:"count}'
top-15:35:05up1day,26min,3users,loadaverage:0.00,0.01,0.05
Tasks:225total,1running,224sleeping,0stopped,0zombie
%Cpu(s):2.5us,10.0sy,0.0ni,87.5id,0.0wa,0.0hi,0.0si,0.0st
KiBMem:1421760total,104516free,777344used,539900buff/cache
KiBSwap:2097148total,2071152free,25996used.456028availMem
PIDUSERPRNIVIRTRESSHRS%CPU%MEMTIME+COMMAND
TotalstatusD:
sar
通过sar -u 3可以查看CUP总体消耗占比:
[root@localhost~]#sar-u3
Linux3.10.0-1062.el7.x86_64(localhost.localdomain)2020年05月01日_x86_64_(2CPU)
15时18分03秒CPU%user%nice%system%iowait%steal%idle
15时18分06秒all0.000.000.170.000.0099.83
15时18分09秒all0.000.000.170.000.0099.83
15时18分12秒all0.170.000.170.000.0099.66
15时18分15秒all0.000.000.000.000.00100.00
15时18分18秒all0.000.000.000.000.00100.00
%user:用户空间的CPU使用。%nice:改变过优先级的进程的CPU使用率。%system:内核空间的CPU使用率。%iowait:CPU等待IO的百分比 。%steal:虚拟机的虚拟机CPU使用的CPU。%idle:空闲的CPU。
在以上的显示当中,主要看%iowait和%idle:
若 %iowait的值过高,表示硬盘存在I/O瓶颈;若 %idle的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量;若 %idle的值持续低于 10,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU;
定位线上最耗CPU的线程
准备工作
启动一个程序。arthas-demo是一个简单的程序,每隔一秒生成一个随机数,再执行质因数分解,并打印出分解结果。
curl-Ohttps://alibaba.github.io/arthas/arthas-demo.jar
java-jararthas-demo.jar
[root@localhost~]#curl-Ohttps://alibaba.github.io/arthas/arthas-demo.jar
%Total%Received%XferdAverageSpeedTimeTimeTimeCurrent
DloadUploadTotalSpentLeftSpeed
1003743100374300302200:00:010:00:01--:--:--3023
[root@localhost~]#java-jararthas-demo.jar
1813=7*7*37
illegalArgumentCount:1,numberis:-180005,need>=2
illegalArgumentCount:2,numberis:-111175,need>=2
18505=5*3701
166691=7*23813
105787=11*59*163
60148=2*2*11*1367
196983=3*3*43*509
illegalArgumentCount:3,numberis:-173479,need>=2
illegalArgumentCount:4,numberis:-112840,need>=2
39502=2*19751
....
通过top命令找到最耗时的进程
[root@localhost~]#top
top-11:11:05up20:02,3users,loadaverage:0.09,0.07,0.05
Tasks:225total,1running,224sleeping,0stopped,0zombie
%Cpu(s):0.0us,0.7sy,0.0ni,99.3id,0.0wa,0.0hi,0.0si,0.0st
KiBMem:1421760total,135868free,758508used,527384buff/cache
KiBSwap:2097148total,2070640free,26508used.475852availMem
Changedelayfrom3.0to
PIDUSERPRNIVIRTRESSHRS%CPU%MEMTIME+COMMAND
98344root20024225522350812108S0.71.70:00.32java
1root20019410062443184S0.00.40:20.41systemd
2root200000S0.00.00:00.12kthreadd
4root0-20000S0.00.00:00.00kworker/0:0H
6root200000S0.00.00:20.25ksoftirqd/0
找到进程号是98344。
找到进程中最耗CUP的线程
使用ps -Lp #pid cu命令,查看某个进程中的线程CPU消耗排序:
[root@localhost~]#ps-Lp98344cu
USERPIDLWP%CPUNLWP%MEMVSZRSSTTYSTATSTARTTIMECOMMAND
root98344983440.0104.1242255259060pts/0Sl+11:090:00java
root98344983450.0104.1242255259060pts/0Sl+11:090:04java
root98344983460.0104.1242255259060pts/0Sl+11:090:01VMThread
root98344983470.0104.1242255259060pts/0Sl+11:090:00ReferenceHandl
root98344983480.0104.1242255259060pts/0Sl+11:090:00Finalizer
root98344983490.0104.1242255259060pts/0Sl+11:090:00SignalDispatch
root98344983500.0104.1242255259060pts/0Sl+11:090:05C2CompilerThre
root98344983510.0104.1242255259060pts/0Sl+11:090:00C1CompilerThre
root98344983520.0104.1242255259060pts/0Sl+11:090:00ServiceThread
root98344983530.1104.1242255259060pts/0Sl+11:090:19VMPeriodicTas
看TIME列可以看出那个线程耗费CUP多,根据LWP列可以看到线程的ID号,但是需要转换成16进制才可以查询线程堆栈信息。
获取线程id的十六进制码
使用printf '%x\n' 98345命令做进制转换:
[root@localhost~]#printf'%x\n'98345
18029
查看线程堆栈信息
使用jstack获取堆栈信息jstack 98344 | grep -A 10 18029:
[root@localhost~]#jstack98344|grep-A1018029
"main"#1prio=5os_prio=0tid=0x00007fb88404b800nid=0x18029waitingoncondition[0x00007fb88caab000]
java.lang.Thread.State:TIMED_WAITING(sleeping)
atjava.lang.Thread.sleep(NativeMethod)
atjava.lang.Thread.sleep(Thread.java:340)
atjava.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
atdemo.MathGame.main(MathGame.java:17)
"VMThread"os_prio=0tid=0x00007fb8840f2800nid=0x1802arunnable
"VMPeriodicTaskThread"os_prio=0tid=0x00007fb884154000nid=0x18031waitingoncondition
通过命令我们可以看到这个线程的对应的耗时代码是在demo.MathGame.main(MathGame.java:17)
grep-C5foofile显示file文件里匹配foo字串那行以及上下5行
grep-B5foofile显示foo及前5行
grep-A5foofile显示foo及后5行
网络瓶颈
定位丢包,错包情况
watch more /proc/net/dev用于定位丢包,错包情况,以便看网络瓶颈,重点drop(包被丢弃)和网络包传送的总量,不要超过网络上限:
[root@localhost~]#watch-n2more/proc/net/dev
Every2.0s:more/proc/net/devFriMay117:16:552020
Inter-|Receive|Transmit
face|bytespacketserrsdropfifoframecompressedmulticast|bytespacketserrsdropfifocollscarriercompressed
lo:1002513000000010025130000000
ens33:75909807156966100000019335572225551000000
最左边的表示接口的名字,Receive表示收包,Transmit表示发送包; bytes:表示收发的字节数;packets:表示收发正确的包量;errs:表示收发错误的包量;drop:表示收发丢弃的包量;
查看路由经过的地址
traceroute ip可以查看路由经过的地址,常用来统计网络在各个路由区段的耗时,如:
[root@localhost~]#traceroute14.215.177.38
tracerouteto14.215.177.38(14.215.177.38),30hopsmax,60bytepackets
1CD-HZTK5H2.mshome.net(192.168.137.1)0.126ms**
2***
310.250.112.3(10.250.112.3)12.587ms12.408ms12.317ms
4172.16.227.230(172.16.227.230)2.152ms2.040ms1.956ms
5172.16.227.202(172.16.227.202)11.884ms11.746ms12.692ms
6172.16.227.65(172.16.227.65)2.665ms3.143ms2.923ms
7171.223.206.217(171.223.206.217)2.834ms2.752ms2.654ms
8182.150.18.205(182.150.18.205)5.145ms5.815ms5.542ms
9110.188.6.33(110.188.6.33)3.514ms171.208.199.185(171.208.199.185)3.431ms171.208.199.181(171.208.199.181)10.768ms
10202.97.29.17(202.97.29.17)29.574ms202.97.30.146(202.97.30.146)32.619ms*
11113.96.5.126(113.96.5.126)36.062ms113.96.5.70(113.96.5.70)35.940ms113.96.4.42(113.96.4.42)45.859ms
1290.96.135.219.broad.fs.gd.dynamic.163data.com.cn(219.135.96.90)35.680ms35.468ms35.304ms
1314.215.32.102(14.215.32.102)35.135ms14.215.32.110(14.215.32.110)35.613ms14.29.117.242(14.29.117.242)54.712ms
14*14.215.32.134(14.215.32.134)49.518ms14.215.32.122(14.215.32.122)47.652ms
15***
...
查看网络错误
netstat -i可以查看网络错误:
[root@localhost~]#netstat-i
KernelInterfacetable
IfaceMTURX-OKRX-ERRRX-DRPRX-OVRTX-OKTX-ERRTX-DRPTX-OVRFlg
ens331500570291000225897000BMRU
lo65536130000130000LRU
Iface: 网络接口名称;MTU: 最大传输单元,它限制了数据帧的最大长度,不同的网络类型都有一个上限值,如:以太网的MTU是1500;RX-OK:接收时,正确的数据包数。RX-ERR:接收时,产生错误的数据包数。RX-DRP:接收时,丢弃的数据包数。RX-OVR:接收时,由于过速(在数据传输中,由于接收设备不能接收按照发送速率传送来的数据而使数据丢失)而丢失的数据包数。TX-OK:发送时,正确的数据包数。TX-ERR:发送时,产生错误的数据包数。TX-DRP:发送时,丢弃的数据包数。TX-OVR:发送时,由于过速而丢失的数据包数。Flg:标志,B 已经设置了一个广播地址。L 该接口是一个回送设备。M 接收所有数据包(混乱模式)。N 避免跟踪。O 在该接口上,禁用ARP。P 这是一个点到点链接。R 接口正在运行。U 接口处于“活动”状态。
包的重传率
cat /proc/net/snmp用来查看和分析240秒内网络包量,流量,错包,丢包。通过RetransSegs和OutSegs来计算重传率tcpetr=RetransSegs/OutSegs。
[root@localhost~]#cat/proc/net/snmp
Ip:ForwardingDefaultTTLInReceivesInHdrErrorsInAddrErrorsForwDatagramsInUnknownProtosInDiscardsInDeliversOutRequestsOutDiscardsOutNoRoutesReasmTimeoutReasmReqdsReasmOKsReasmFailsFragOKsFragFailsFragCreates
Ip:164241708000002387242255171500000000
Icmp:InMsgsInErrorsInCsumErrorsInDestUnreachsInTimeExcdsInParmProbsInSrcQuenchsInRedirectsInEchosInEchoRepsInTimestampsInTimestampRepsInAddrMasksInAddrMaskRepsOutMsgsOutErrorsOutDestUnreachsOutTimeExcdsOutParmProbsOutSrcQuenchsOutRedirectsOutEchosOutEchoRepsOutTimestampsOutTimestampRepsOutAddrMasksOutAddrMaskReps
Icmp:14900509900000000014701470000000000
IcmpMsg:InType3InType11OutType3
IcmpMsg:5099147
Tcp:RtoAlgorithmRtoMinRtoMaxMaxConnActiveOpensPassiveOpensAttemptFailsEstabResetsCurrEstabInSegsOutSegsRetransSegsInErrsOutRstsInCsumErrors
Tcp:1200120000-13766004236711223186292040
Udp:InDatagramsNoPortsInErrorsOutDatagramsRcvbufErrorsSndbufErrorsInCsumErrors
Udp:140543801896000
UdpLite:InDatagramsNoPortsInErrorsOutDatagramsRcvbufErrorsSndbufErrorsInCsumErrors
UdpLite:0000000
重传率=292/223186≈0.13%
平均每秒新增TCP连接数:通过/proc/net/snmp文件得到最近240秒内PassiveOpens的增量,除以240得到每秒的平均增量; 机器的TCP连接数 :通过/proc/net/snmp文件的CurrEstab得到TCP连接数; 平均每秒的UDP接收数据报:通过/proc/net/snmp文件得到最近240秒内InDatagrams的增量,除以240得到平均每秒的UDP接收数据报; 平均每秒的UDP发送数据报:通过/proc/net/snmp文件得到最近240秒内OutDatagrams的增量,除以240得到平均每秒的UDP发送数据报;
磁盘瓶颈
查磁盘空间
查看磁盘剩余空间
查看磁盘剩余空间使用df -hl命令:
[root@localhost~]#df-hl
文件系统容量已用可用已用%挂载点
devtmpfs678M0678M0%/dev
tmpfs695M0695M0%/dev/shm
tmpfs695M28M667M4%/run
tmpfs695M0695M0%/sys/fs/cgroup
/dev/mapper/centos_aubin-root27G5.6G22G21%/
/dev/sda11014M211M804M21%/boot
查看磁盘已使用空间
du -sh命令是查看磁盘已使用空间的情况,这里的“已使用的磁盘空间”意思是指定的文件下的整个文件层次结构所使用的空间,在没给定参数的情况下,du报告当前目录所使用的磁盘空间。其实就是显示文件或目录所占用的磁盘空间的情况:
[root@localhost~]#du-sh
64K
-h:输出文件系统分区使用的情况,例如:10KB,10MB,10GB等。-s:显示文件或整个目录的大小,默认单位是KB。
!!
du的详细信息可以通过man du查看。
查看磁盘读写情况
查看磁盘总体读写情况
通iostat查看磁盘总体的读写情况:
[root@localhost~]#iostat
Linux3.10.0-1062.el7.x86_64(localhost.localdomain)2020年05月02日_x86_64_(2CPU)
avg-cpu:%user%nice%system%iowait%steal%idle
0.170.000.200.460.0099.17
Device:tpskB_read/skB_wrtn/skB_readkB_wrtn
sda1.5630.4539.6146596206060644
scd00.000.020.0031020
dm-01.9630.0138.4245919985878155
dm-10.090.090.301384045328
tps:该设备每秒的传输次数。kB_read/s:每秒从设备(drive expressed)读取的数据量;kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;
查看磁盘详细读写情况
通过iostat -x 1 3可以看到磁盘详细读写情况,没隔一秒输出一次一共输出3次,当看到I/O等待时间所占CPU时间的比重很高的时候,首先要检查的就是机器是否正在大量使用交换空间,同时iowait占比cpu的消耗是否很大,如果大说明磁盘存在大的瓶颈,同时await,表示磁盘的响应时间以便小于5ms:
[root@localhost~]#iostat-x13
Linux3.10.0-1062.el7.x86_64(localhost.localdomain)2020年05月02日_x86_64_(2CPU)
avg-cpu:%user%nice%system%iowait%steal%idle
0.170.000.200.460.0099.16
Device:rrqm/swrqm/sr/sw/srkB/swkB/savgrq-szavgqu-szawaitr_awaitw_awaitsvctm%util
sda0.010.490.630.9530.5939.7889.580.34214.2349.16323.488.551.34
scd00.000.000.000.000.020.0098.480.001.211.210.000.950.00
dm-00.000.000.621.3530.1538.5969.700.91460.6749.12648.546.661.31
dm-10.000.000.020.070.090.308.520.04442.7495.43521.176.910.06
avg-cpu表示总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值:
%user:CPU处在用户模式下的时间百分比。%nice:CPU处在带NICE值的用户模式下的时间百分比。%system:CPU处在系统模式下的时间百分比。%iowait:CPU等待输入输出完成时间的百分比,如果%iowait的值过高,表示硬盘存在I/O瓶颈。%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。%idle:CPU空闲时间百分比,如果%idle值高,表示CPU较空闲;如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量;如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。。
Device表示设备信息:
rrqm/s:每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并wrqm/s:每秒对该设备的写请求被合并次数r/s:每秒完成的读次数w/s:每秒完成的写次数rkB/s:每秒读数据量(kB为单位)wkB/s:每秒写数据量(kB为单位)avgrq-sz:平均每次IO操作的数据量(扇区数为单位)avgqu-sz:平均等待处理的IO请求队列长度await:平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)svctm:平均每次IO请求的处理时间(毫秒为单位)%util:一秒中有百分之多少的时间用于 I/O如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷。idle小于70% IO压力就较大了,一般读取速度有较多的wait。
!!
iostat -xmd 1 3:新增m选项可以在输出是使用M为单位。
查看最耗IO的进程
一般先通过iostat查看是否存在io瓶颈,再使用iotop命令来定位那个进程最耗费IO:
[root@localhost~]#iotop
TotalDISKREAD:0.00B/s|TotalDISKWRITE:0.00B/s
ActualDISKREAD:0.00B/s|ActualDISKWRITE:0.00B/s
TIDPRIOUSERDISKREADDISKWRITESWAPINIO>COMMAND
123931be/4root0.00B/s0.00B/s0.00%0.02%[kworker/1:30]
94208be/4xiaolyuh0.00B/s0.00B/s0.00%0.00%nautilus-desktop--force[gmain]
1be/4root0.00B/s0.00B/s0.00%0.00%systemd--system--deserialize62
2be/4root0.00B/s0.00B/s0.00%0.00%[kthreadd]
94211be/4xiaolyuh0.00B/s0.00B/s0.00%0.00%gvfsd-trash--spawner:1.4/org/gtk/gvfs/exec_spaw/0
4be/0root0.00B/s0.00B/s0.00%0.00%[kworker/0:0H]
6be/4root0.00B/s0.00B/s0.00%0.00%[ksoftirqd/0]
7rt/4root0.00B/s0.00B/s0.00%0.00%[migration/0]
8be/4root0.00B/s0.00B/s0.00%0.00%[rcu_bh]
9be/4root0.00B/s0.00B/s0.00%0.00%[rcu_sched]
10be/0root0.00B/s0.00B/s0.00%0.00%[lru-add-drain]
...
通过iotop -p pid可以查看单个进程的IO情况:
[root@localhost~]#iotop-p124146
TotalDISKREAD:0.00B/s|TotalDISKWRITE:0.00B/s
ActualDISKREAD:0.00B/s|ActualDISKWRITE:0.00B/s
TIDPRIOUSERDISKREADDISKWRITESWAPINIO>COMMAND
124146be/4root0.00B/s0.00B/s0.00%0.00%java-jararthas-demo.jar
应用瓶颈
查看某个进程的PID
如查看java的进程的pid,ps -ef | grep java:
[root@localhost~]#ps-ef|grepjava
root1241461984009:13pts/000:00:06java-jararthas-demo.jar
root12521098378010:07pts/100:00:00grep--color=autojava
查看特定进程的数量
如查看java进程的数量,ps -ef | grep java| wc -l:
[root@localhost~]#ps-ef|grepjava|wc-l
2
查看线程是否存在死锁
查看线程是否存在死锁,jstack -l pid:
[root@localhost~]#jstack-l124146
2020-05-0210:13:38
FullthreaddumpOpenJDK64-BitServerVM(25.252-b09mixedmode):
"C1CompilerThread1"#6daemonprio=9os_prio=0tid=0x00007f27f013c000nid=0x1e4f9waitingoncondition[0x0000000000000000]
java.lang.Thread.State:RUNNABLE
Lockedownablesynchronizers:
-None
"C2CompilerThread0"#5daemonprio=9os_prio=0tid=0x00007f27f012d000nid=0x1e4f8waitingoncondition[0x0000000000000000]
java.lang.Thread.State:RUNNABLE
Lockedownablesynchronizers:
-None
"main"#1prio=5os_prio=0tid=0x00007f27f004b800nid=0x1e4f3waitingoncondition[0x00007f27f7274000]
java.lang.Thread.State:TIMED_WAITING(sleeping)
atjava.lang.Thread.sleep(NativeMethod)
atjava.lang.Thread.sleep(Thread.java:340)
atjava.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
atdemo.MathGame.main(MathGame.java:17)
Lockedownablesynchronizers:
-None
...
查看某个进程的线程数
ps -efL | grep [PID] | wc -l,如:
[root@localhost~]#ps-efL|grep124146|wc-l
12
查看具体有哪些线程用ps -Lp [pid] cu:
[root@localhost~]#ps-Lp124146cu
USERPIDLWP%CPUNLWP%MEMVSZRSSTTYSTATSTARTTIMECOMMAND
root1241461241460.0112.5248911635724pts/0Sl+09:130:00java
root1241461241470.0112.5248911635724pts/0Sl+09:130:01java
root1241461241480.0112.5248911635724pts/0Sl+09:130:00VMThread
root1241461241490.0112.5248911635724pts/0Sl+09:130:00ReferenceHandl
root1241461241500.0112.5248911635724pts/0Sl+09:130:00Finalizer
root1241461241510.0112.5248911635724pts/0Sl+09:130:00SignalDispatch
root1241461241520.0112.5248911635724pts/0Sl+09:130:00C2CompilerThre
root1241461241530.0112.5248911635724pts/0Sl+09:130:00C1CompilerThre
root1241461241540.0112.5248911635724pts/0Sl+09:130:00ServiceThread
root1241461241550.1112.5248911635724pts/0Sl+09:130:05VMPeriodicTas
root1241461253620.0112.5248911635724pts/0Sl+10:130:00AttachListener
统计所有的log文件中,包含Error字符的行
find / -type f -name "*.log" | xargs grep "ERROR",这个在排查问题过程中比较有用:
[root@localhost~]#find/-typef-name"*.log"|xargsgrep"ERROR"
/var/log/tuned/tuned.log:2020-03-1318:05:59,145ERRORtuned.utils.commands:Writingtofile'/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor'error:'[Errno19]Nosuchdevice'
/var/log/tuned/tuned.log:2020-03-1318:05:59,145ERRORtuned.utils.commands:Writingtofile'/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor'error:'[Errno19]Nosuchdevice'
/var/log/tuned/tuned.log:2020-04-2814:55:34,857ERRORtuned.utils.commands:Writingtofile'/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor'error:'[Errno19]Nosuchdevice'
/var/log/tuned/tuned.log:2020-04-2814:55:34,859ERRORtuned.utils.commands:Writingtofile'/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor'error:'[Errno19]Nosuchdevice'
/var/log/tuned/tuned.log:2020-04-2815:23:19,037ERRORtuned.utils.commands:Writingtofile'/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor'error:'[Errno19]Nosuchdevice'
...
应用启动时指定JVM参数
java -jar -Xms128m -Xmx1024m -Xss512k -XX:PermSize=128m -XX:MaxPermSize=64m -XX:NewSize=64m -XX:MaxNewSize=256m arthas-demo.jar,如:
[root@localhost~]#java-jar-Xms128m-Xmx1024m-Xss512k-XX:PermSize=128m-XX:MaxPermSize=64m-XX:NewSize=64m-XX:MaxNewSize=256marthas-demo.jar
OpenJDK64-BitServerVMwarning:ignoringoptionPermSize=128m;supportwasremovedin8.0
OpenJDK64-BitServerVMwarning:ignoringoptionMaxPermSize=64m;supportwasremovedin8.0
157518=2*3*3*3*2917
illegalArgumentCount:1,numberis:-187733,need>=2
illegalArgumentCount:2,numberis:-102156,need>=2
173379=3*57793
总结
在使用linux命令时,如果想看帮助可以使用--help或者man查看帮助信息:
[root@localhost~]#grep--help
用法:grep[选项]...PATTERN[FILE]...
在每个 FILE 或是标准输入中查找 PATTERN。
默认的 PATTERN 是一个基本正则表达式(缩写为 BRE)。
例如:grep-i'helloworld'menu.hmain.c
...
[root@localhost~]#mangrep
GREP(1)GeneralCommandsManualGREP(1)
NAME
grep,egrep,fgrep-打印匹配给定模式的行
总览SYNOPSIS
grep[options]PATTERN[FILE...]
grep[options][-ePATTERN|-fFILE][FILE...]
描述DESCRIPTION
Grep搜索以FILE命名的文件输入(或者是标准输入,如果没有指定文件名,或者给出的文件名是-的话),寻找含有与给定的模式PATTERN
...
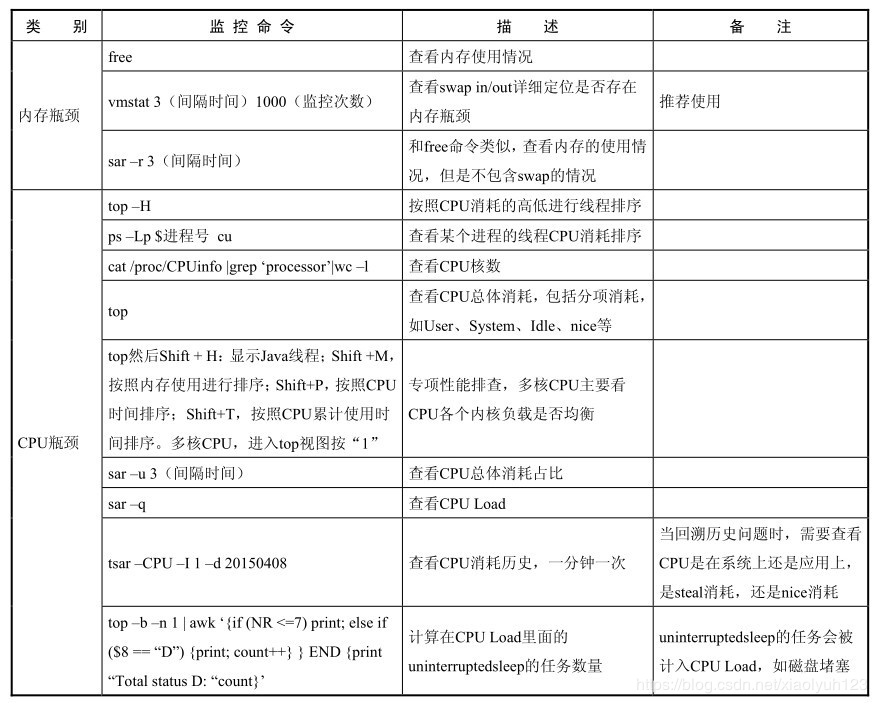
| 类别 | 监控命令 | 描述 | 备注 |
|---|---|---|---|
| 内存瓶颈 | free | 查看内存使用 | |
| vmstat 3(间隔时间) 100(监控次数) | 查看swap in/out详细定位是否存在性能瓶颈 | 推荐使用 | |
| sar -r 3 | 和free命令类似,查看内存的使用情况,但是不包含swap的情况 | ||
| cpu瓶颈 | top -H | 按照cpu消耗高低进行排序 | |
| ps -Lp 进程号 cu | 查看某个进程的cpu消耗排序 | ||
| cat /proc/cpuinfo |grep 'processor'|wc -l | 查看cpu核数 | ||
| top | 查看cpu总体消耗,包括分项消耗如user,system,idle,nice等消耗 | ||
| top 然后shift+h:显示java线程,然后shift+M:按照内存使用进行排序;shift+P:按照cpu时间排序;shift+T:按照cpu累计使用时间排序多核cpu,按“1”进入top视图 | 专项性能排查,多核CPU主要看CUP各个内核的负载情况 | ||
| sar -u 3(间隔时间) | 查看cpu总体消耗占比 | ||
| sar -q | 查看cpu load | ||
| top -b -n 1 | awk '{if (NR<=7)print;else if($8=="D"){print;count++}}END{print "Total status D:"count}' | 计算在cpu load里面的uninterruptedsleep的任务数量 uninterruptedsleep的任务会被计入cpu load,如磁盘堵塞 | ||
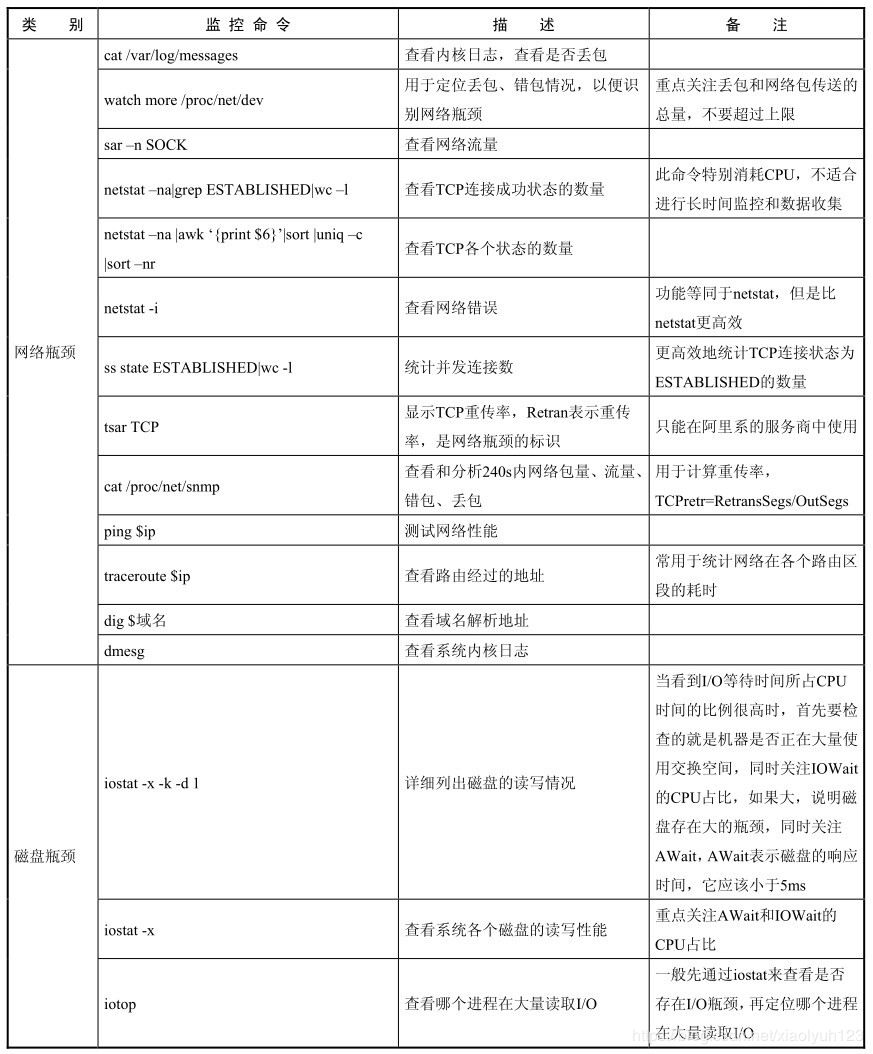
| 网络瓶颈 | cat /var/log/messages | 查看内核日志,查看是否丢包 | |
| watch more /proc/net/dev | 用于定位丢包,错包情况,以便看网络瓶颈 | 重点drop(包被丢弃)和网络包传送的总量,不要超过网络上限 | |
| sar -n SOCK | 查看网络流量 | ||
| netstat -na|grep ESTABLISHED|wc -l | 查看tcp连接成功状态的数量 | 此命令特别消耗cpu,不适合进行长时间监控数据收集 | |
| netstat -na|awk'{print $6}'|sort |uniq -c |sort -nr | 看tcp各个状态数量 | ||
| netstat -i | 查看网络错误 | ||
| ss state ESTABLISHED| wc -l | 更高效地统计tcp连接状态为ESTABLISHED的数量 | ||
| cat /proc/net/snmp | 查看和分析240秒内网络包量,流量,错包,丢包 | 用于计算重传率tcpetr=RetransSegs/OutSegs | |
| ping $ip | 测试网络性能 | ||
| traceroute $ip | 查看路由经过的地址 | 常用于定位网络在各个路由区段的耗时 | |
| dig $域名 | 查看域名解析地址 | ||
| dmesg | 查看系统内核日志 | ||
| 磁盘瓶颈 | iostat -x -k -d 1 | 详细列出磁盘的读写情况 | 当看到I/O等待时间所占CPU时间的比重很高的时候,首先要检查的就是机器是否正在大量使用交换空间,同时iowait占比cpu的消耗是否很大,如果大说明磁盘存在大的瓶颈,同时await,表示磁盘的响应时间以便小于5ms |
| iostat -x | 查看系统各个磁盘的读写性能 | 重点await和iowait的cpu占比 | |
| iotop | 查看哪个进程在大量读取IO | 一般先通过iostat查看是否存在io瓶颈,再定位哪个进程在大量读取IO | |
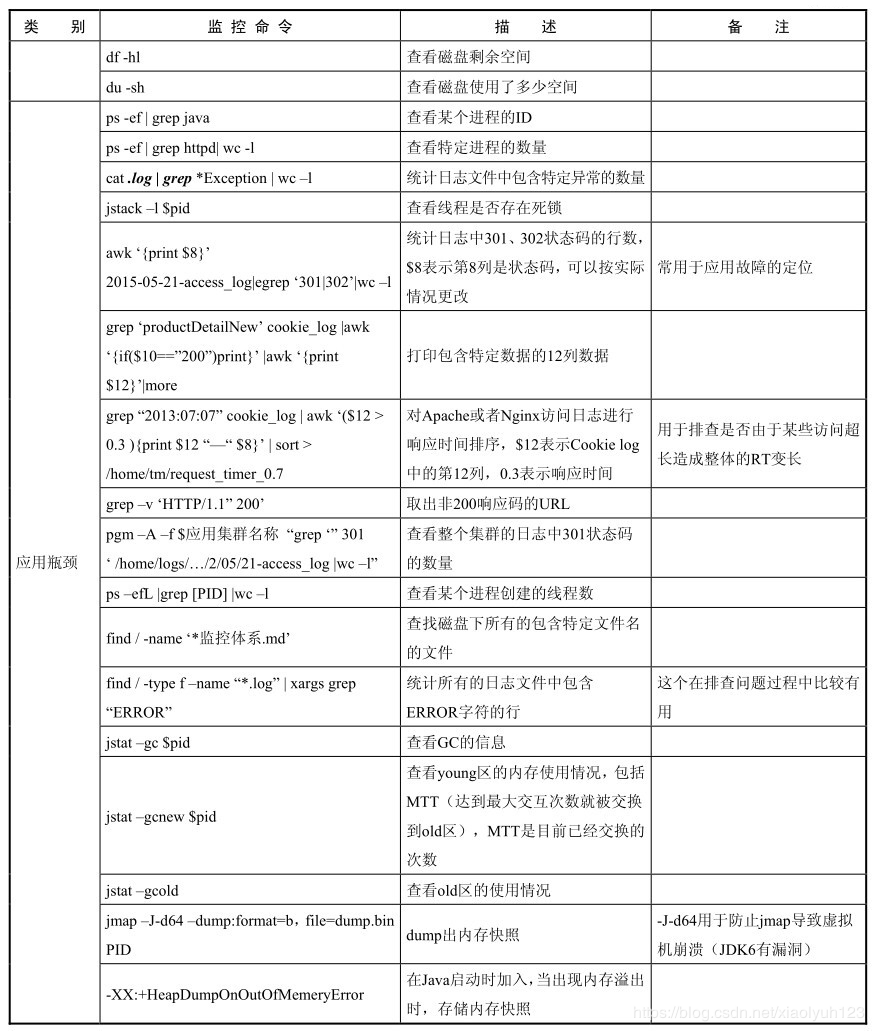
| df -hl | 查看磁盘剩余空间 | ||
| du -sh | 查看磁盘使用了多少空间 | ||
| 应用瓶颈 | ps -ef | grep java | 查看某个进程的id号 |
| ps -ef | grep httpd| wc -l | 查看特定进程的数量 | ||
| cat ***.log | grep ***Exception| wc -l | 统计日志文件中包含特定异常数量 | ||
| jstack -l pid | 用于查看线程是否存在死锁 | ||
| awk'{print $8}' 2017-05-22-access_log|egrep '301|302'| wc -l | 统计log中301、302状态码的行数,$8表示第八列是状态码,可以根据实际情况更改 | 常用于应用故障定位 | |
| grep 'wholesaleProductDetailNew' cookie_log | awk '{if($10=="200")}'print}' | awk 'print $12' | more | 打印包含特定数据的12列数据 | |
| grep "2017:05:22" cookielog | awk '($12>0.3){print 8}' | sort > 目录地址 | 对apache或者nginx访问log进行响应时间排序,$12表示cookie log中的12列表示响应时间 用于排查是否是由于是某些访问超长造成整体的RT变长 | ||
| grep -v 'HTTP/1.1" 200' | 取出非200响应码的URL | ||
| pgm -A -f $应用集群名称 "grep "'301' log文件地址 | wc -l" | 查看整个集群的log中301状态码的数量 | ||
| ps -efL | grep [PID] | wc -l | 查看某个进程创建的线程数 | ||
| find / -type f -name "*.log" | xargs grep "ERROR" | 统计所有的log文件中,包含Error字符的行 | 这个在排查问题过程中比较有用 | |
| jstat -gc [pid] | 查看gc情况 | ||
| jstat -gcnew [pid] | 查看young区的内存使用情况,包括MTT(最大交互次数就被交换到old区),TT是目前已经交换的次数 | ||
| jstat -gcold | 查看old区的内存使用情况 | ||
| jmap -J-d64 -dump:format=b,file=dump.bin PID | dump出内存快照 | -J-d64防止jmap导致虚拟机crash(jdk6有bug) | |
| -XX:+HeapDumpOnOutOfMemeryError | 在java启动时加入,当出现内存溢出时,存储内存快照 | ||
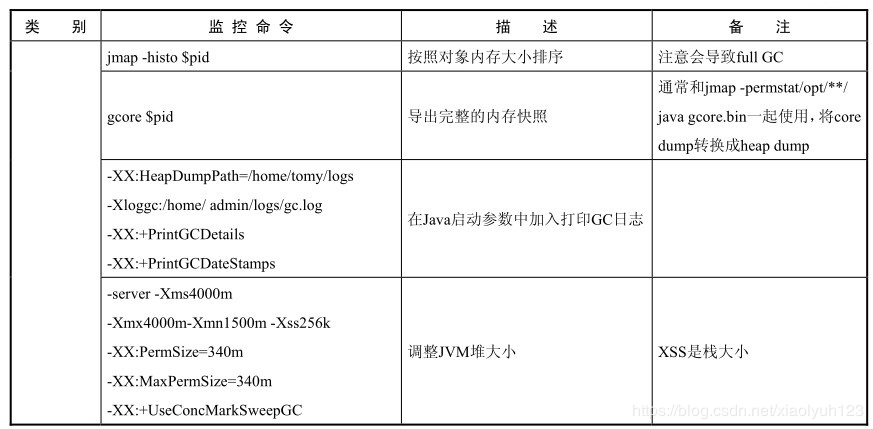
| jmap -histo [pid] | 按照对象内存大小排序 | 注意会导致full gc | |
| gcore [pid] | 导出完成的内存快照 | 通常和jmap -permstat /opt/**/java gcore.bin一起使用,将core dump转换成heap dump | |
| -XX:HeapDumpPath=/home/logs -Xloggc:/home/log/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps | 在Java启动参数中加入,打印gc日志 | ||
| -server -Xms4000m -Xmx4000m -Xmn1500m -Xss256k -XX:PermSize=340m -XX:MaxPermSize=340m -XX:+UseConcMarkSweepGC | 调整JVM堆大小 | xss是栈大小 |

往期推荐
一起进大厂,每日学干货


点击“”,领取 2021年最新免费技术资料大全



![[JAVA] JAVA开发前后端分离企业级上线项目 JAVA对接真实数据项目前后端真实项目开发课程](https://static.kouhao8.com/sucaidashi/xkbb/19ff207a049a913ed76cb6264db11b0a.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)






















相关资源