

懒人技巧:python快速复制请求头
发布于 2021-04-17 00:56 ,所属分类:知识学习综合资讯
上篇文章 懒人技巧:python短网址恢复 小懒提出会开个小专题专门分享一些小技能,妙招,或者编程技巧,放在次头条。
今天给大家分享一个小懒最近发现的trick,非常实用~
快速复制请求头
平时有用python写爬虫的朋友,应该知道如果遇到爬不到网页内容的时候应该是遇到了反扒,这时候加个header试试,有时候加host,有时候甚至要加上cookie,反正模拟得越像浏览器真实请求就越不容易被反扒。
很多需要登录的内容就百分百需要加上cookie了。
我们在写header请求头的时候,需要将header写成字典的形式。比如:
headers={
'user-agent':'Mozilla/5.0(WindowsNT10.0;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/87.0.4280.88Safari/537.36',
'origin':'https://xxx.com',
'referer':'https://wx.zsxq.com/',
'Cookie':cookie,
}
于是在浏览器的network里就不得不一个个复制过来,直接复制的话还得一个个加双引号,逗号。
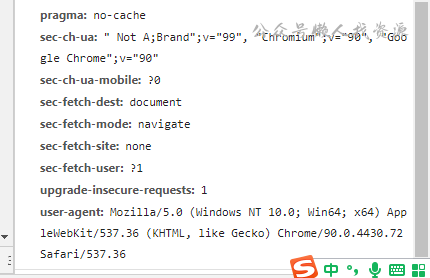
把时间浪费在这种无意义的复制粘贴实在不是小懒的风格。
不想这么麻烦的肯定不是小懒一个人,于是网上一搜,果然找到工具!
网址:https://curl.trillworks.com/

用法如上图,在开发工具中选中请求copy as curl,然后粘贴到网站表单中,获得Python代码。
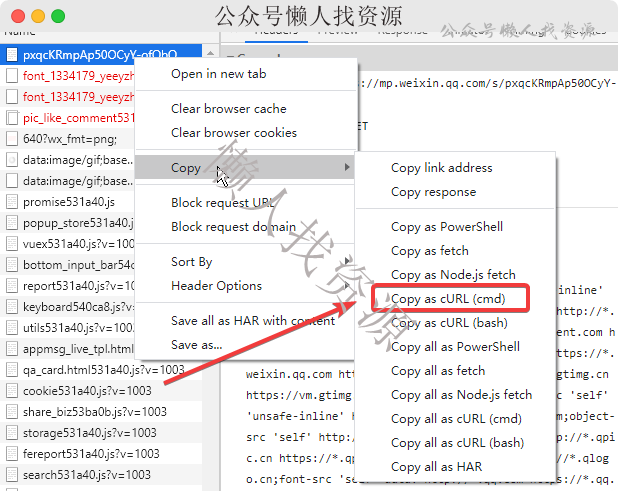
原理很简单,网络请求里的curl是包括各种协议和参数设置甚至cookie设置。
复制到网站直接帮我们转化成代码!

连请求的代码都帮你写好了!
支持Python, Ansible URI, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSON, Elixir, Rust
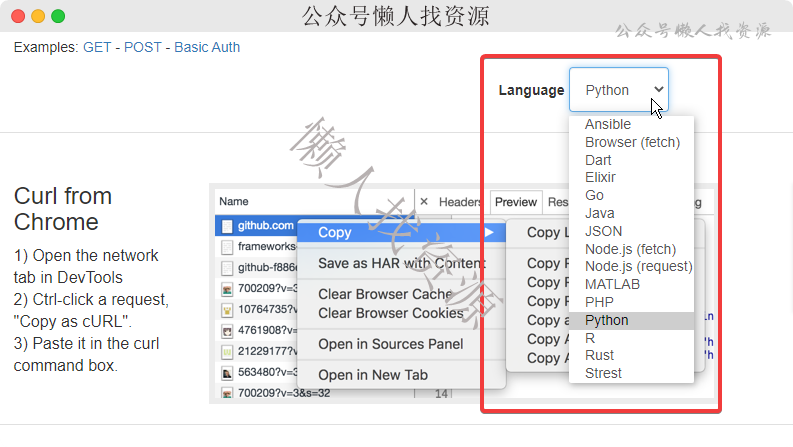
然后直接复制到编译器,自己再去写后续就行啦~
网址:https://curl.trillworks.com/
希望可以帮你更快得写代码。
毕竟人生苦短,我才用python啦~

![高中地理必修2知识点总结,快速复习备考![百度云资源]](https://static.kouhao8.com/cunchu/cunchu7/2023-05-18/UpFile/defaultuploadfile/230505ml3/10-1.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[Python] 马老师 30天快速入门 快速掌握编程技巧 python从入门到精通视频(全60集)](https://static.kouhao8.com/sucaidashi/xkbb/0fe1d6eac4fa8fc8feb1b0e398c66355.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![Python的人工智能深度学习框架Tensorflow 入门视频教程+源码 [复制链接]](https://static.kouhao8.com/sucaidashi/xkbb/653dcd1a86323be436637425dbcbdd76.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[Python] Python快速入门视频教程 快速掌握Python基础课程 猎豹网校Python视频教程](https://static.kouhao8.com/sucaidashi/xkbb/4c014989f94980d95f9022d89ce7cda5.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)









![[Java框架] 一头扎进SpringBoot视频教程](https://static.kouhao8.com/sucaidashi/xkbb/3fbc1b60f358791aa1f347356a3720bd.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


![[Python爬虫] 2017年最新整理Python爬虫零基础快速入门精品教程](https://static.kouhao8.com/sucaidashi/xkbb/386e0037ea793d08861567965a03f2b4.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)






相关资源