

企业急需,人才急缺,大数据到底应该如何学?
发布于 2021-09-04 15:06 ,所属分类:软件编程学习资料









·Storm流式计算
· 分布式协调服务:Zookeeper
· NOSQL数据库:Redis、MongoDB
·还有RabbitMQ、Impala、Flink、Kylin
· 机器学习:Mahout
·……
· Hive
· Sqoop
· Flume
· Kafka
·Spark基于内存计算的框架
· Spark Core最为重要
· SparkSQL
· Spark Streaming
· 图计算
· 机器学习


-End-

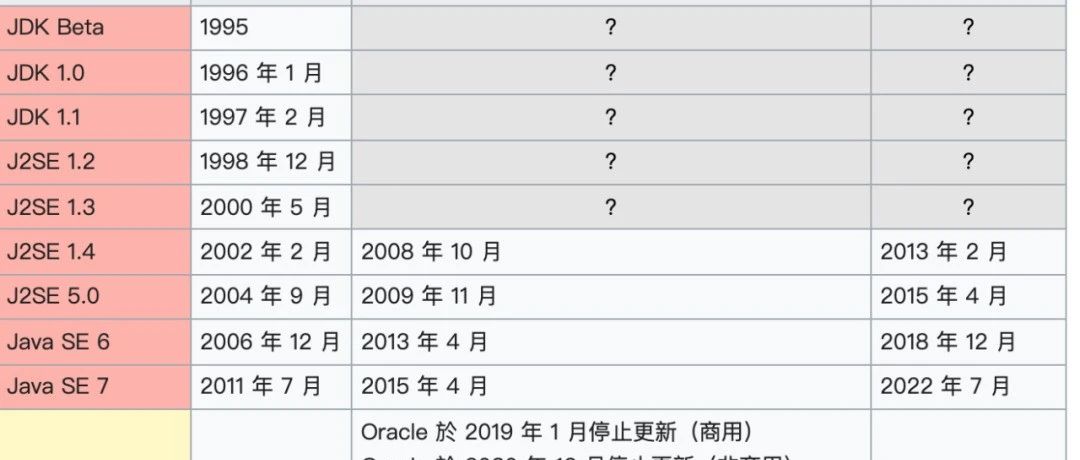
Java 程序员可以学习的技术方向,精通任何一个都可以成为专家
今天我 devops 了一下

实战篇:断点续传?文件秒传?手撸大文件上传
 可乐记得加冰,爱我就要置顶
可乐记得加冰,爱我就要置顶


 素质三连biubiubiu~
素质三连biubiubiu~



![[大数据] GeoHash企业级大数据 用户画像实战应用项目 GeoHash大数据项目实战](https://static.kouhao8.com/sucaidashi/xkbb/ff24ea3604353362b6f96d6ef711ca4e.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[大数据] 15周全 大数据的统计学基础视频教程 炼数成金大数据基础课程](https://static.kouhao8.com/sucaidashi/xkbb/28d0d56e9273980c266a93f2a7ac17e0.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)



![[数据仓库] 炼数成金数据挖掘视频教程 大数据分析视频 基于案例学数据挖掘 大数据技术的具体实现](https://static.kouhao8.com/sucaidashi/xkbb/1658e78f4a490be019e84c51f74568ab.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[数据挖掘] 数据挖掘与分析应用+电商数据化运营+轻松驾驭统计学+EXCEL大数据分](https://static.kouhao8.com/sucaidashi/xkbb/e4942238b92e56e454abb60596981b02.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[数据库] 企业级Oracle海量数据架构设计DBA培训视频 13课 送完整pdf笔记 大数据职业规划](https://static.kouhao8.com/sucaidashi/xkbb/127582cbf0bf2409ff73151bfda26e25.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![Hadoop] 云帆大数据 8天70集 实战开发视频 Hadoop从入门到上手企业开发](https://static.kouhao8.com/sucaidashi/xkbb/e81e6de8dbd24b280383bcbff47efa9d.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[Hadoop] 云帆大数据 8天70集 实战开发视频 Hadoop从入门到上手企业开发](https://static.kouhao8.com/sucaidashi/xkbb/45fa6408c8ece2929433dd8d7e12d90f.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[大数据] Java Virtual Machine大数据性能优化学习 大数据JVM性能优化实战视频教程](https://static.kouhao8.com/sucaidashi/xkbb/0c481b0dcc6d3b541c970a5fd816effa.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[大数据] 当大数据融入金融行业 炼数成金大数据课程 金融投资原理量化投资实战金融行业大数据](https://static.kouhao8.com/sucaidashi/xkbb/b9148172888b966279d278caf637bd11.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

相关资源