说明:本文节选自机械工业出版社新出版的《深入剖析Java虚拟机:源码剖析与实例详解(基础卷)》(作者:马智)一书。本文以图解的方式介绍了Java虚拟机中GC的复制算法和“标记-整理”算法的相关内容,该内容在网络上的相关资料很少,希望对各位读者学习相关知识有所帮助。

------------------------------------------------------------HotSpot VM中的所有垃圾收集器采用的都是分代收集算法,针对年轻代通常采用的是复制算法,老年代可以采用“标记-清除”或“标记-整理”算法。Serial收集器采用的是复制算法,而Serial Old收集器采用的是“标记-整理”算法。
1.复制算法
最简单的复制(Copying)算法就是将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块内存用完后,将活的对象标记出来,然后把这些活对象复制到另外一块空闲区域上,最后再把已使用过的内存空间完全清理掉。这样每次都是对整个半区进行内存回收,内存分配时也不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现方法简单,运行高效。但是这种算法的代价是将内存缩小了一半。由于系统中大部分对象的生命周期非常短暂,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块较大的Eden空间和两块较小的Survivor空间(即From Survivor空间和To Survivor空间),每次使用Eden和From Survivor空间。当回收时,将Eden和From Survivor空间中还存活的对象一次性地复制到To Survivor空间,最后清理Eden和FromSurvivor空间。HotSpot VM默认Eden:Survivor为8:1,也就是每次新生代中可用内存空间为整个新生代容量的90%(其中一块Survivor不可用),只有10%的内存会被“浪费”。当然,大部分的对象可回收只是针对一般场景中的数据而言的,我们没有办法保证每次回收时只有不多于10% 的对象存活,当To Survivor空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保(Handle Promotion)。下面详细介绍Serial收集器采用的复制算法。
(1)初始引用状态。
年轻代划分为Eden空间、From Survivor空间和To Survivor空间,初始的引用状态如图1所示。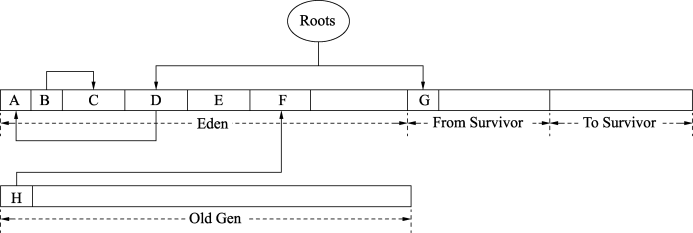
在Eden和From Survivor空间中有根集Roots对对象的引用,这些对象都是活跃对象。因为Serial收集器不回收老年代,所以老年代引用的年轻代对象也会被认为是活跃对象。如图2所示,年轻代首先从根集出发标记出根集直接引用的活跃对象,为D和G,并且在标记的过程中就会将D和G复制到To Survivor空间,复制完成后调整根集引用,此时直接引用的就是D’和G’。在将D和G标记为活跃对象的同时,其实还会在D和G的markOop中设置转发指针,这样如果还有其他引用指向D和G,那么只需要调整为指向D’和G’即可。
如图3所示,对于D和G中引用的对象还没有标记和复制,因此会遍历D’和G’中的引用对象并标记复制。注意,此时遍历的是D’和G’,而不是D和G对象。在To Survivor空间中会有4个非常重要的指针用来辅助遍历引用的对象,如图4所示。
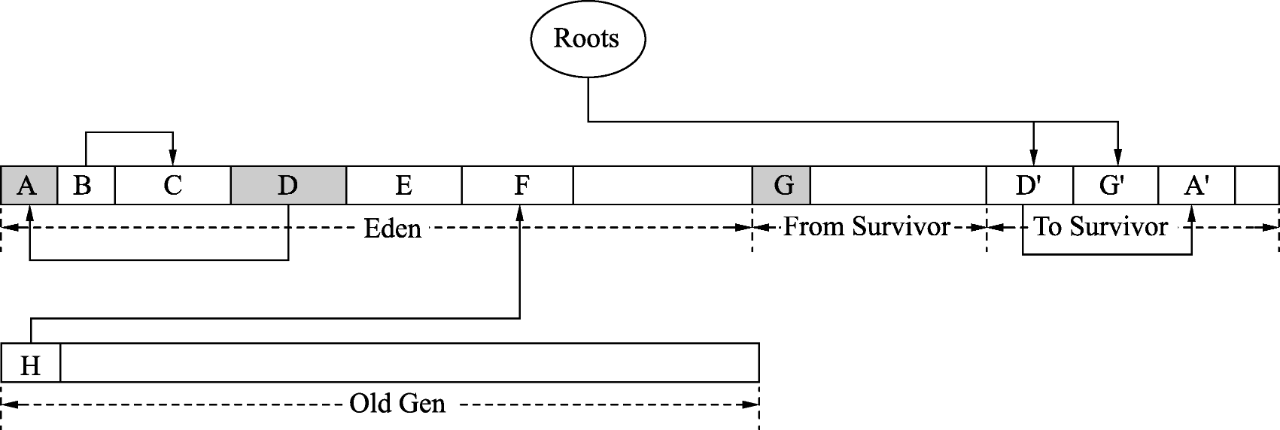
图3 标记根间接引用的对象并复制

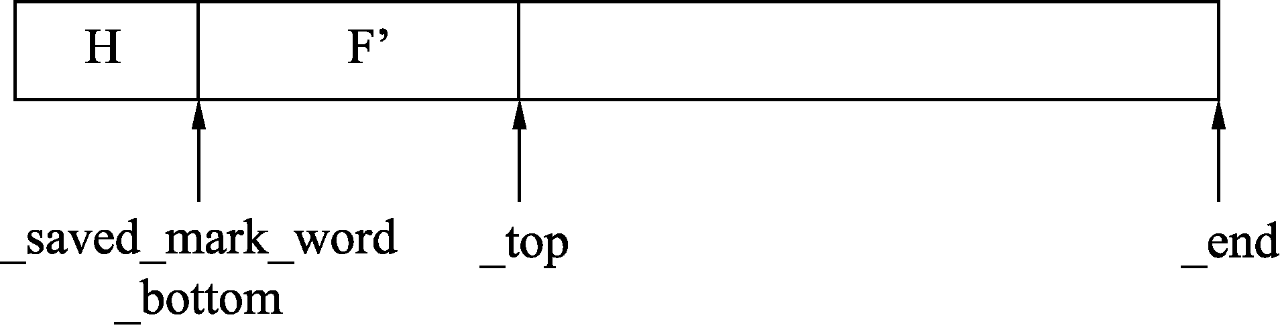
_bottom和_saved_mark_word指针之间是已分配内存并且已扫描完的对象,也就是对象引用的其他对象已经处理完成;_saved_mark_word和_top指针之间是已分配内存但是没有扫描的对象,也就是对象引用的其他对象还没有处理。
对于图3来说,初始的_bottom和_saved_mark_word指针指向D’的开始处,而_top指针指向G’的结尾处,那么D’和G’表示的就是已分配内存但是没有扫描的对象,如图5所示。
Serial收集器首先处理D’,将D’引用的A对象标记并复制到To Survivor中,还要调整D’的引用指向最新的A’。处理完D’引用的所有对象后,各指针位置的指向如图6所示。
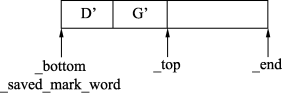
图5遍历D’与G’时各指针的指向
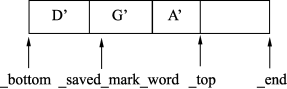
图6扫描完D’直接引用的所有对象后各指针的指向
下一次就是扫描G’并做和D’相同的处理,直到_saved_mark_word等于_top时表示处理完了所有活跃的对象。遍历活跃对象可以看作是遍历一张有向图,采用以上方式进行遍历,其中_saved_ mark_word和_top指针其实是维护了一个隐式扫描队列,通过此队列完成图的广度遍历。由于年轻代的复制算法只针对年轻代进行回收,所以老年代引用的年轻代对象都被视为活跃对象。图7中的H对象引用了年轻代的F对象,此时的F对象就是活跃对象。H对象很可能不是活跃的,那么F对象也就是死亡的,但是仍然会被当作活跃对象来处理,于是便产生了“浮动垃圾”。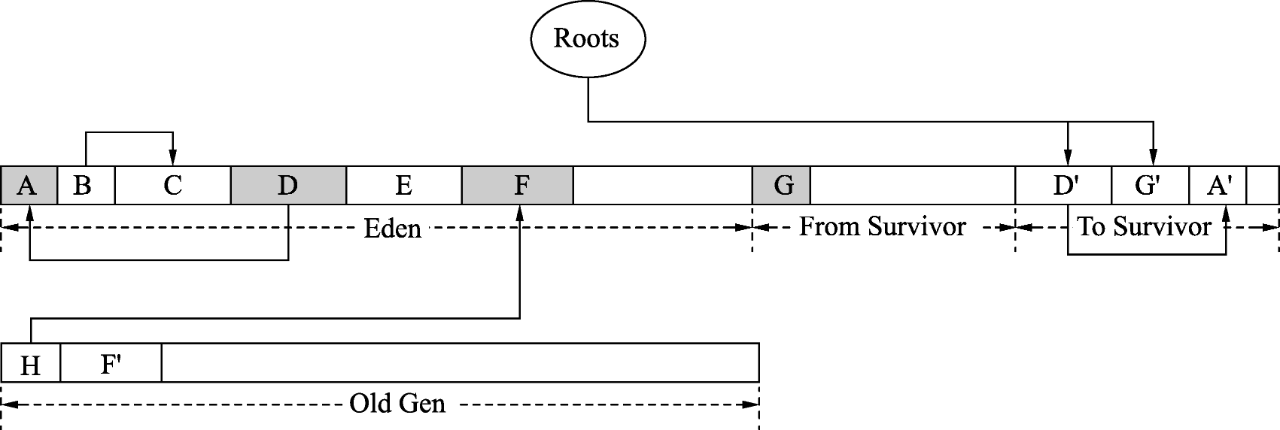
当F对象过大,在To Survivor空间中无法开辟存储空间时,就会晋升到老年代F’处(老年代的分配担保)。如果F对象也有对其他年轻代对象的引用,则必须扫描F’对象。其实在老年代中同样会有_bottom、_saved_mark_word等指针,只是在初始状态时,_bottom和_saved_mark_word指向的是F’的开始地址而不是H,如图8所示。
2.“标记-整理”算法
复制算法在对象存活率较高时需要进行较多的复制操作,效率将会变低,更关键的是如果不想浪费过多的内存空间,就需要有额外的空间进行分配担保,以应对被使用的内存中对象存活过多的情况,因此老年代一般不能直接选用复制算法。老年代中一般是一些生命周期较长的对象,Serial Old收集器采用“标记-整理”(Mark-Compact)算法进行回收,标记过程与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理端边界以外的内存,这样能够避免产生更多的内存碎片。在分配内存时可直接移动堆顶指针,按顺序分配内存,同时也容易为大对象找到可分配的内存,但复制会降低内存回收效率。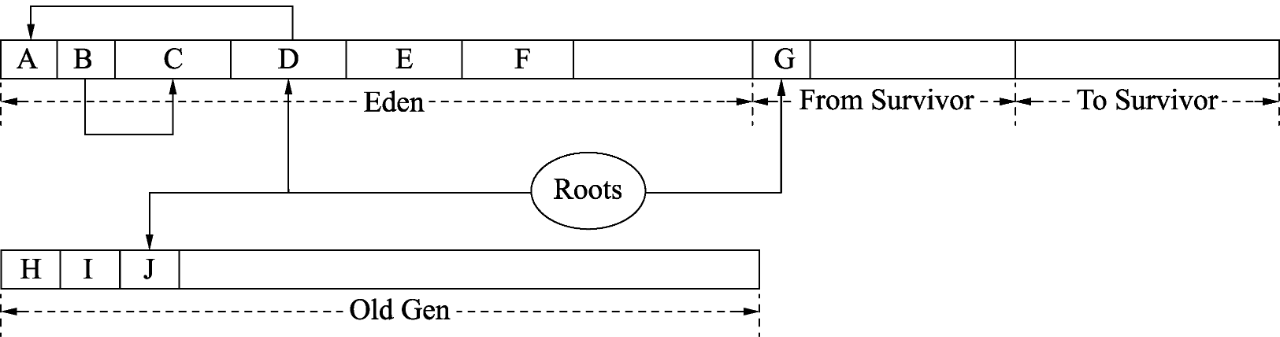
无论年轻代还是老年代,必须要将根集直接或间接引用的对象都标记出来,如图10所示。这样就不会错标活跃对象。另外,用户线程(后面也称为Mutator线程)在执行GC时都是停止的,因此不会产生对象的变更,这样也不会产生漏标等情况,是精确式GC。将Eden、From Survivor和To Survivor(在YGC失败时,To Survivor空间可能也存在对象)空间中的所有对象都进行压缩,当Eden空间不够时,可能会选取From Survivor和To Survivor空间继续进行压缩;老年代的对象压缩在老年代空间中。压缩过程中会计算每个对象被压缩整理之后的位置,同时将新的位置编码进对象的markOop中,还要更新引用指针指向新的位置,如图11所示。
图10标记活跃对象
需要注意的是,压缩之前和压缩之后的顺序保持不变,即如果压缩之前A之后是D,那么压缩之后仍然是A之后为D。这是压缩整理算法的一大特点,因为相邻的对象一般都有很强的关联性,所以可以更高效地获取数据。
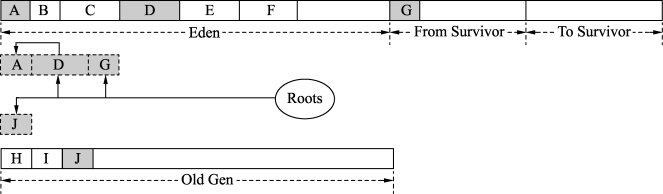
图11 计算压缩-整理后的地址
将活跃对象移动到markOop中保存的转发指针指向的地址即可,如图12所示。
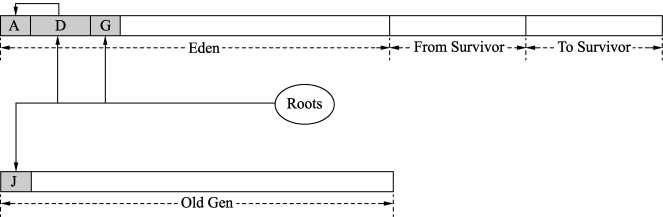
图12 复制对象到新的地址






![[项目实战] 深入理解Java虚拟机(jvm性能调优+内存模型+虚拟机原理)](https://static.kouhao8.com/sucaidashi/xkbb/9014d96b529c467adefb7e358ab95918.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[Java基础] 圣思园 深入Java虚拟机系列教学视频 高清](https://static.kouhao8.com/sucaidashi/xkbb/b364dba1a2c78a4c48253ac45aa2d605.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


![[JAVA] 深入JVM内核—原理、诊断与优化 JVM教程+PPT+作业 JAVA虚拟机高性能优化视频](https://static.kouhao8.com/sucaidashi/xkbb/ca6c1f3f4d1532b281ecdc1542c96831.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[数据结构与算法] JAVA数据结构和算法系列视频教程 20课](https://static.kouhao8.com/sucaidashi/xkbb/45aaeda975311f2601ac736ca894176c.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[数据结构与算法] JAVA数据结构和算法系列视频教程 20课](https://static.kouhao8.com/sucaidashi/xkbb/e4942238b92e56e454abb60596981b02.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


![[数据结构与算法] JAVA数据结构和算法系列视频教程 20课](https://static.kouhao8.com/sucaidashi/xkbb/24316e54024f990721ba7ae1820c981e.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[JAVA] 直通BAT算法实战课程-JAVA算法数据结构课程 算法进阶班视频教程实战视频](https://static.kouhao8.com/sucaidashi/xkbb/a21d39440aed4f45beacba236fc119f1.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[人工智能] 视频教程 看的见的算法 7个经典应用诠释算法精髓](https://static.kouhao8.com/sucaidashi/xkbb/82a642e21bab222d46c01251e39ea7fa.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)



相关资源