

python基础基础数据类型-补充
发布于 2021-04-17 05:42 ,所属分类:知识学习综合资讯
目录
循环列表改变大小的问题
循环字典改变大小的问题
基础数据类型的转换
基础数据类型的分类
详解
循环列表,改变列表大小的问题
列表 li = [11, 22, 33, 44, 55]
把索引为奇数对应的元素删除
(不能一个一个删除,这个列表只是举个例子,里面的元素不不确定)。
正常思路:
(正向循环删除列表元素)
循环列表,然后进行判断,只要索引为奇数就删除。
li = [11, 22, 33, 44, 55]for index in range(len(li)):if index % 2 == 1:li.pop(index)print(li) # [11, 33, 44]
(左右滑动查看完整代码)
据题意,这个题最终的结果应该是:li = [11, 33, 55],但是得到的结果却是: li = [11, 33, 44]
第一次循环,index为0,原列表内容不删除;
第二次循环,index为1,将元素22删除(此时列表中33,44,55都会往前进一位,他们的索引由原来的2,3,4变成了1,2,3);
第三次循环,index为2,原列表内容不删除;
第四次循环,index为3,此时原列表索引为3的位置对应元素为55,将元素55删除;
第五次循环,index为4,原列表内容不删除。
正向循环一个列表时,如果删除某个元素,那么这个元素后面的所有元素都会向前进一位,他们的索引相比之前也会前进一位。
解决方式
1.直接删除
通过del()利用切片删除列表元素
li = [11, 22, 33, 44, 55]del li[1::2]print(li) # [11, 33, 55]
(左右滑动查看完整代码)
2.倒序删除
通过倒序循环删除列表元素
li = [11, 22, 33, 44, 55]for index in range(len(li)-1, -1, -1):if index % 2 == 1:li.pop(index)print(li) # [11, 33, 55]
(左右滑动查看完整代码)
第一次循环,index为4,原列表内容不删除;
第二次循环,index为3,将元素44删除(此时列表中33,44,55都会往前进一位,他们的索引由原来的2,3,4变成了1,2,3);
第三次循环,index为2,原列表内容不删除;
第四次循环,index为1,此时原列表索引为1的位置对应元素为22,将元素22删除;
第五次循环,index为0,原列表内容不删除。
倒序删除元素,每次删除元素,此元素后面的元素的索引虽然也发生变化,但是不会影响最终结果。
3.思维置换
把原列表索引为偶数的元素取出来放在一个新列表中,然后把新列表赋值给原列表
li = [11, 22, 33, 44, 55]new_li = []for index in range(len(li)):if index % 2 == 0:new_li.append(li[index])li = new_liprint(li) # [11, 33, 55]
(左右滑动查看完整代码)
总结
在循环一个列表的过程中,最好不要改变列表的大小(增加值、删除值),如果要改变列表的大小,那么结果很可能会出错或者报错。
循环字典,改变字典大小的问题
字典dic = {'k1': 'pamela', 'k2': 'apple', 'k3': 'abc', 'age': 18}
将字典中键含有 'k' 元素的键值对删除
(不能一个一个删除,这个字典只是举个例子,里面的元素不确定)。
正常思路:
循环遍历所有的键,然后进行判断,只要键含有 'k' 元素就删除此键值对。
dic = {'k1': 'pamela', 'k2': 'apple', 'k3': 'abc', 'age': 18}for key in dic:if 'k' in key:dic.pop(key)print(dic) # RuntimeError: dictionary changed size during iteration
(左右滑动查看完整代码)
执行发现报错了,字典在循环时,只要改变大小,就会报错。
解决方式
1.直接删除
循环转换成列表的keys(),删除字典中的键值对
dic = {'k1': 'pamela', 'k2': 'apple', 'k3': 'abc', 'age': 18}for key in list(dic.keys()):if 'k' in key:dic.pop(key)print(dic) # {'age': 18}
(左右滑动查看完整代码)
2.思维置换
把字典中含有 'k' 元素的键取出来放在一个列表中,循环列表,删除字典中对应的键值对
dic = {'k1': 'pamela', 'k2': 'apple', 'k3': 'abc', 'age': 18}li = []for key in dic:if 'k' in key:li.append(key)for i in li:dic.pop(i)print(dic) # {'age': 18}
(左右滑动查看完整代码)
总结
在循环一个字典的过程中,不要改变字典的大小(增加、删除字典的元素),如果要改变字典的大小,那么会直接报错。
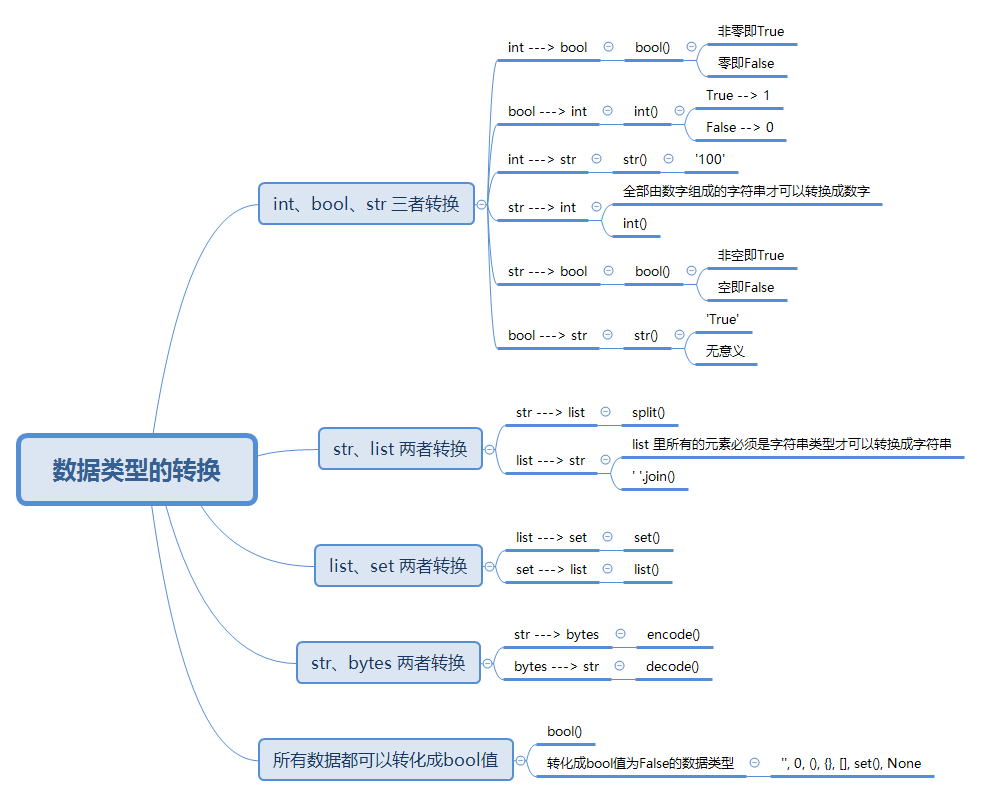
基础数据类型的转换
基础数据类型有:int、bool、str、list、tuple、dict、set,这些数据类型之间都可以相互转换。
(点击查看大图)
int、bool、str 三者转换
'''int <---> bool'''# int ---> boolnum1 = 100print(bool(num1)) # True (非零即True)num2 = 0print(bool(num2)) # False (零即False)# bool ---> intt = Trueprint(int(t)) # 1 (True --> 1)t = Falseprint(int(t)) # 0 (False --> 0)
(左右滑动查看完整代码)
'''int <---> str'''# int ---> strnum = 100print(str(num)) # '100'# str ---> int # 全部由数字组成的字符串才可以转换成数字s1 = '90'print(int(s1)) # 90
(左右滑动查看完整代码)
'''str <---> bool'''# str ---> bools1 = 'pamela'print(bool(s1)) # True (非空即True)s2 = ' ' # 有空格print(bool(s2)) # Trues3 = '' # 空字符串print(bool(s3)) # False (空即False)# bool ---> str 无意义t1 = Trueprint(str(True)) # 'True'
(左右滑动查看完整代码)
str、list 两者转换
'''str <---> list'''# str ---> lists1 = 'pamela 中文 apple'print(s1.split()) # ['pamela', '中文', 'apple']# list ---> str # list 里所有的元素必须是字符串类型才可以转换成字符串l1 = ['pamela', '中文', 'apple']print(' '.join(l1)) # 'pamela 中文 apple'
(左右滑动查看完整代码)
list、set 两者转换
'''list <---> set'''# list ---> set 去重l1 = [1, 2, 3, 3]print(set(l1)) # {1, 2, 3}# set ---> listset1 = {1, 2, 3}print(list(set1)) # [1, 2, 3]
(左右滑动查看完整代码)
str、bytes 两者转换
在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码,比如:UTF-8编码、GBK编码等。
bytes类型(python基础数据类型之一)也称作字节文本,主要用途就是网络的数据传输,与数据存储。bytes与str差不多,操作方法也很相似。
'''str ---> bytesencode 编码(把Unicode编码转换成非Unicode编码)'''s1 = '中文'b1 = s1.encode('utf-8') # 转化成utf-8的bytes类型print(b1) # b'\xe4\xb8\xad\xe6\x96\x87'b2 = s1.encode('gbk') # 转化成gbk的bytes类型print(b2) # b'\xd6\xd0\xce\xc4'
(左右滑动查看完整代码)
'''bytes ---> strdecode 解码(把非Unicode编码转换成Unicode编码)用什么方式编码就用什么方式解码,否则会报错'''b3 = b'\xe4\xb8\xad\xe6\x96\x87's3 = b3.decode('utf-8') # 解码 utf-8的bytes类型print(s3) # '中文'b4 = b'\xd6\xd0\xce\xc4's4 = b4.decode('gbk') # 解码 gbk的bytes类型print(s4) # '中文'
(左右滑动查看完整代码)
'''非Unicode编码之间相互转换非Unicode编码先转换成Unicode编码,再把Unicode编码转换成另一种非Unicode编码例:gbk ---> utf-8gbk先解码成Unicode,再编码成utf-8'''b1 = b'\xd6\xd0\xce\xc4' # gbk的'中文's1 = b1.decode('gbk') # 解码 转化成Unicode的'中文'b2 = s1.encode('utf-8') # 编码 转化成utf-8的'中文'print(b2) # b'\xe4\xb8\xad\xe6\x96\x87'
(左右滑动查看完整代码)
所有数据都可以转化成bool值
'''转化成bool值为False的数据类型有:'', 0, (), {}, [], set(), None'''
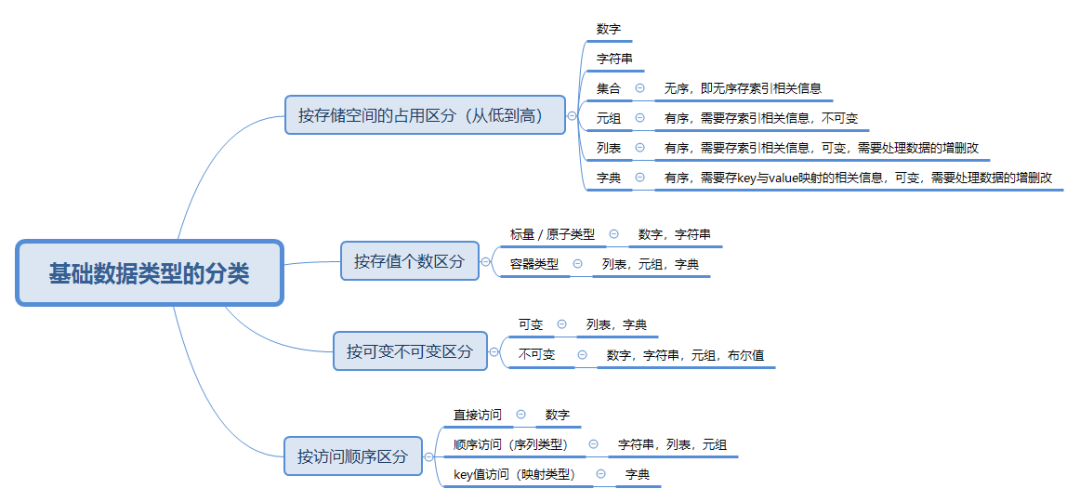
基础数据类型的分类
(点击查看大图)


![[Python] 徐老师大数据Python培训教程视频 28集Python全新零基础培训视频教程 徐老](https://static.kouhao8.com/sucaidashi/xkbb/570b1b552a766843b416fb28f2752248.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[Python基础] 2018年最新Python3数据科学入门与实战视频教程+代码讲义 8章](https://static.kouhao8.com/sucaidashi/xkbb/03b77b9ef3563422128ce04d404e3b08.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


![[Python基础] Python零基础入门学习视频教程全42集](https://static.kouhao8.com/sucaidashi/xkbb/78b9d826631a1cf627f1eff51b54368b.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[Python基础] 小甲鱼零基础入门Python学习视频+全套源码课件 Python视频教程 96讲](https://static.kouhao8.com/sucaidashi/xkbb/d7970e7abb546e6cbe9a4c45b030ed51.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[Hadoop] 炼数成金Hadoop大数据之JAVA开发基础 学习Hadoop必备Java基础课程 大数据基础视频](https://static.kouhao8.com/sucaidashi/xkbb/69b955b64636bcdf4fc0ea57eef7881f.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[Python基础] 小甲鱼零基础入门Python学习视频+全套源码课件 Python视频教程 96讲](https://static.kouhao8.com/sucaidashi/xkbb/f52ff23b8362685092ffda6c5fe1dbad.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


![[Python] 零基础入门Python数据分析师到项目实战 多个网易真实案例实战 进阶算法学习视频](https://static.kouhao8.com/sucaidashi/xkbb/ab3d2c0ae37f1b2a7858a9b9daa86d6b.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[Python基础] Python Web开发基础入门视频教程 目前最适合Python入门的视频教程 系统](https://static.kouhao8.com/sucaidashi/xkbb/4f5c0cfab097fd030c7abdf05b57013f.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[Python基础] Python Web开发基础入门视频教程 目前最适合Python入门的视频教程 系统学习Python](https://static.kouhao8.com/sucaidashi/xkbb/c5d2bb19e1f9dd55f599179051f766e3.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)


![[Python] 某机构Python基础班视频教程 13天课程 195个视频 非常接地气 Python编程基础教程](https://static.kouhao8.com/sucaidashi/xkbb/e842684397e882f374ce618ef1e850dd.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[大数据] 女讲师!大数据!矩阵计算基础!炼数成金的大数据的矩阵基础视频教程](https://static.kouhao8.com/sucaidashi/xkbb/b9148172888b966279d278caf637bd11.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
相关资源