

golang-goroutine
发布于 2021-11-04 13:54 ,所属分类:软件编程学习资料
go语句:最具特色的go future
官方出品,必属精品:
Don’t communicate by sharing memory; share memory by communicating.
从 Go 语言编程的角度解释,这句话的意思就是:不要通过共享数据来通讯,恰恰相反,要以通讯的方式共享数据。
goroutine
通道(channel)类型的值,可以被用来以通讯的方式共享数据。更具体地说,它一般被用来在不同的 goroutine 之间传递数据。
那么 goroutine 到底代表着什么呢?
goroutine代表着并发编程模型中的用户级线程
os的进程与线程
操作系统本身提供了进程和线程,这两种并发执行程序的工具
进程
进程:描述的就是程序的执行过程,是运行着的程序的代表
一个进程其实就是某个程序运行时的一个产物
静静地躺在那里的代码就是程序的话,那么奔跑着的、正在发挥着既有功能的代码就可以被称为进程
线程
首先,线程总是在进程之内的,它可以被视为进程中运行着的控制流(或者说代码执行的流程)
一个进程至少会包含一个线程。
如果一个进程只包含了一个线程,那么它里面的所有代码都只会被串行地执行。
每个进程的第一个线程都会随着该进程的启动而被创建,它们可以被称为其所属进程的主线程。
相对应的,如果一个进程中包含了多个线程,那么其中的代码就可以被并发地执行。
除了进程的第一个线程之外,其他的线程都是由进程中已存在的线程创建出来的。
也就是说,主线程之外的其他线程都只能由代码显式地创建和销毁。这需要我们在编写程序的时候进行手动控制,操作系统以及进程本身并不会帮我们下达这样的指令,它们只会忠实地执行我们的指令。
不过,在 Go 程序当中,Go 语言的运行时(runtime)系统会帮助我们自动地创建和销毁系统级的线程。这里的系统级线程指的就是刚刚说过的操作系统提供的线程。
用户级线程
对应的用户级线程指的是架设在系统级线程之上的,由用户(或者说我们编写的程序)完全控制的代码执行流程。
用户级线程的创建、销毁、调度、状态变更以及其中的代码和数据都完全需要我们的程序自己去实现和处理。
优势:
因为它们的创建和销毁并不用通过操作系统去做,所以速度会很快 由于不用等着操作系统去调度它们的运行,所以往往会很容易控制并且可以很灵活
劣势:
最明显也最重要的一个劣势就是复杂,一般的程序员可能并不具备并发编程的能力。if我们只使用了系统级线程,那么我们只要指明需要新线程执行的代码片段,并且下达创建或销毁线程的指令就好了,其他的一切具体实现都会由操作系统代劳。 如果使用用户级线程,我们就不得不既是指令下达者,又是指令执行者。我们必须全权负责与用户级线程有关的所有具体实现。 操作系统不但不会帮忙,还会要求我们的具体实现必须与它正确地对接,否则用户级线程就无法被并发地,甚至正确地运行。毕竟我们编写的所有代码最终都需要通过操作系统才能在计算机上执行
听起来就很麻烦
不过别担心,
Go语言不但有着独特的并发编程模型,以及用户级线程goroutine,还拥有强大的用于调度goroutine、对接系统级线程的调度器。
这个调度器是 Go 语言运行时系统的重要组成部分,它主要负责统筹调配 Go 并发编程模型中的三个主要元素,即:G(goroutine 的缩写)、P(processor 的缩写)和 M(machine 的缩写)。
GPM 模型
即:G(goroutine 的缩写)、P(processor 的缩写)和 M(machine 的缩写)
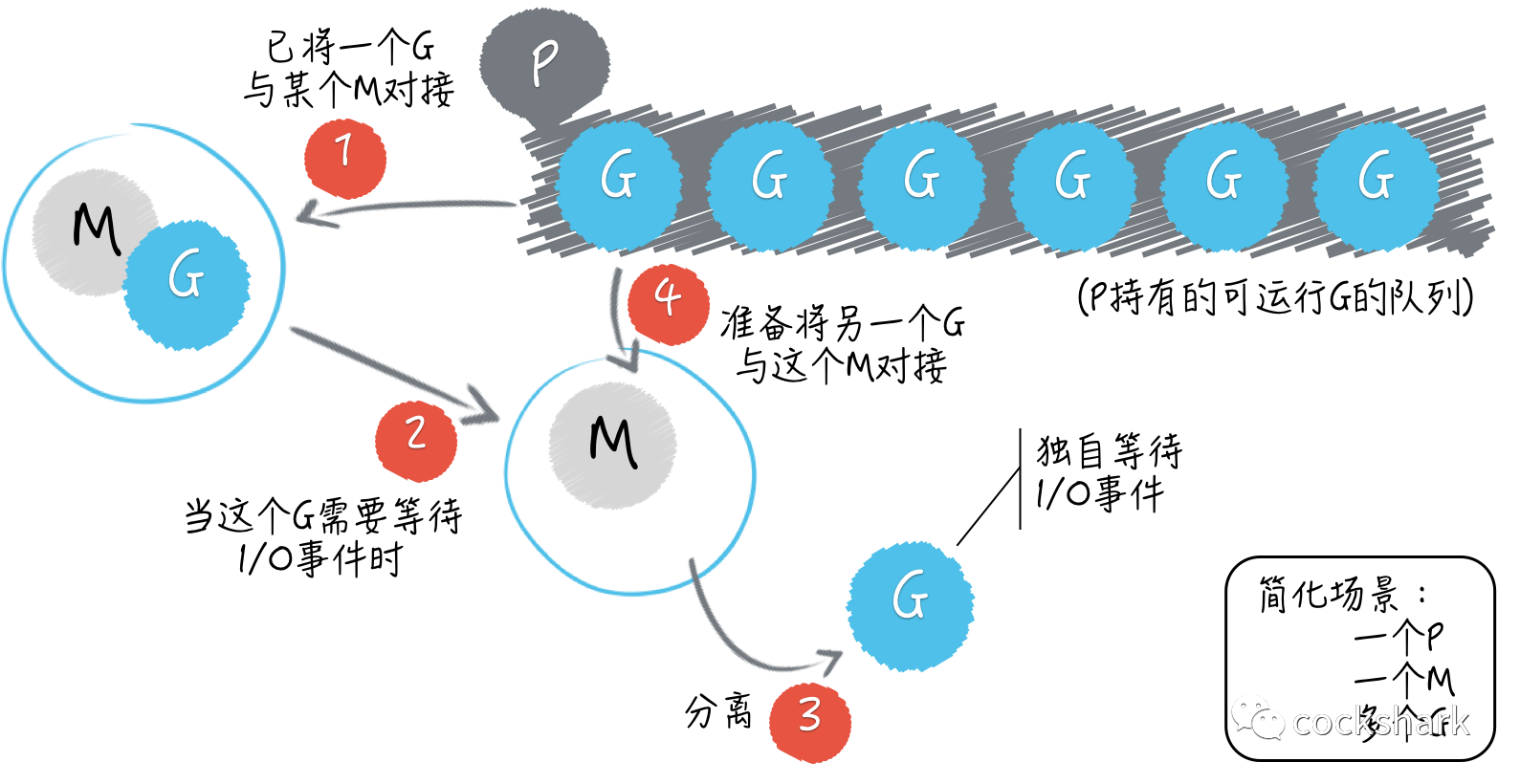
其中的 M 指代的就是系统级线程。而 P 指的是一种可以承载若干个 G,且能够使这些 G 适时地与 M 进行对接,并得到真正运行的中介。
从宏观上说,G 和 M 由于 P 的存在可以呈现出多对多的关系。当一个正在与某个 M 对接并运行着的 G,需要因某个事件(比如等待 I/O 或锁的解除)而暂停运行的时候,调度器总会及时地发现,并把这个 G 与那个 M 分离开,以释放计算资源供那些等待运行的 G 使用。
而当一个 G 需要恢复运行的时候,调度器又会尽快地为它寻找空闲的计算资源(包括 M)并安排运行。另外,当 M 不够用时,调度器会帮我们向操作系统申请新的系统级线程,而当某个 M 已无用时,调度器又会负责把它及时地销毁掉——其实应该是放入了等待队列,不会及时销毁
正因为调度器帮助我们做了很多事,所以我们的 Go 程序才总是能高效地利用操作系统和计算机资源。程序中的所有 goroutine 也都会被充分地调度,其中的代码也都会被并发地运行,即使这样的 goroutine 有数以十万计,也仍然可以如此。
Go 语言实现了一套非常完善的运行时系统,保证了我们的程序在高并发的情况下依旧能够稳定、高效地运行
推荐阅读:《Go 并发编程实战》
那了解了,主线程创建多个子线程, 那么主goroutine的概念存在吗?它与我们启用的其他 goroutine 有什么不同?
funcmain(t*testing.T){
fori:=0;i<10;i++{
// i := i 高版本go 提示需要这样进行一个赋值,for里的变量属于临时变量?
gofunc(){
fmt.Println(i)
}()
}
}
函数中写了一条for语句。这条for语句中的代码会迭代运行 10 次,并有一个局部变量i代表着当次迭代的序号,该序号是从0开始的。
这条for语句中仅有一条go语句,这条go语句中也仅有一条语句。这条最里面的语句调用了fmt.Println函数并想要打印出变量i的值。
这个程序很简单,三条语句逐条嵌套。我的具体问题是:这个命令源码文件被执行后会打印出什么内容?
不会有任何内容被打印出来
如果上面的
main函数改成Test测试函数,那输出就有了,而且还比较奇怪呢
问题解析
为什么上面main函数不会有任何东西被打印?
与一个进程总会有一个主线程类似,每一个独立的 Go 程序在运行时也总会有一个主 goroutine。这个主 goroutine 会在 Go 程序的运行准备工作完成后被自动地启用,并不需要我们做任何手动的操作。
每条
go语句一般都会携带一个函数调用,这个被调用的函数常常被称为go函数。而主 goroutine 的go函数就是那个作为**程序入口的main函数**。
一定要注意,go函数真正被执行的时间,总会与其所属的go语句被执行的时间不同。当程序执行到一条go语句的时候,Go 语言的运行时系统,会先试图从某个存放空闲的 G 的队列中获取一个 G(也就是 goroutine),它只有在找不到空闲 G 的情况下才会去创建一个新的 G。
这也是为什么说“启用”一个 goroutine,而不说“创建”一个 goroutine 的原因。已存在的 goroutine 总是会被优先复用。
然而,创建 G 的成本也是非常低的。创建一个 G 并不会像新建一个进程或者一个系统级线程那样,必须通过操作系统的系统调用来完成,在 Go 语言的运行时系统内部就可以完全做到了,更何况一个 G 仅相当于为需要并发执行代码片段服务的上下文环境而已。
在拿到了一个空闲的 G 之后,Go 语言运行时系统会用这个 G 去包装当前的那个go函数(或者说该函数中的那些代码),然后再把这个 G 追加到某个存放可运行的 G 的队列中。
这类队列中的 G 总是会按照先入先出的顺序,很快地由运行时系统内部的调度器安排运行。虽然这会很快,但是由于上面所说的那些准备工作还是不可避免的,所以耗时还是存在的。
因此,go函数的执行时间总是会明显滞后于它所属的go语句的执行时间。当然了,这里所说的“明显滞后”是对于计算机的 CPU 时钟和 Go 程序来说的。我们在大多数时候都不会有明显的感觉。
在说明了原理之后,我们再来看这种原理下的表象。请记住,只要go语句本身执行完毕,Go 程序完全不会等待go函数的执行,它会立刻去执行后边的语句。这就是所谓的异步并发地执行。
这里“后边的语句”指的一般是for语句中的下一个迭代。然而,当最后一个迭代运行的时候,这个“后边的语句”是不存在的。
所以,为什么不会有任何输出?
在
上面代码中的那条for语句会以很快的速度执行完毕。当它执行完毕时,那 10 个包装了go函数的 goroutine 往往还没有获得运行的机会。
注意,go函数中的那个对fmt.Println函数的调用是以for语句中的变量i作为参数的。
可以想象一下,如果当for语句执行完毕的时候,这些go函数都还没有执行,那么它们引用的变量i的值将会是什么???
它们都会是10,对吗?那么这道题的答案会是“打印出 10 个10”,是这样吗?
在确定最终的答案之前,你还需要知道一个与主 goroutine 有关的重要特性,即:
一旦
主 goroutine中的代码(也就是main函数中的那些代码)执行完毕,当前的 Go 程序就会结束运行。
如此一来,如果在 Go 程序结束的那一刻,还有 goroutine 未得到运行机会,那么它们就真的没有运行机会了,它们中的代码也就不会被执行了。
当for语句的最后一个迭代运行的时候,其中的那条go语句即是最后一条语句。所以,在执行完这条go语句之后,主 goroutine 中的代码也就执行完了,Go 程序会立即结束运行。那么,如果这样的话,还会有任何内容被打印出来吗?
严谨地讲,Go 语言并不会去保证这些 goroutine 会以怎样的顺序运行。由于主 goroutine 会与我们手动启用的其他 goroutine 一起接受调度
又因为调度器很可能会在 goroutine 中的代码只执行了一部分的时候暂停,以期所有的 goroutine 有更公平的运行机会。
所以哪个 goroutine 先执行完、哪个 goroutine 后执行完往往是不可预知的,除非我们使用了某种 Go 语言提供的方式进行了人为干预。然而,在这段代码中,我们并没有进行任何人为干预。
那答案到底是什么呢?就 上面代码 中如此简单的代码而言,绝大多数情况都会是“不会有任何内容被打印出来”。
但是为了严谨起见,无论回答是“打印出 10 个10”还是“不会有任何内容被打印出来”,又或是“打印出乱序的0到9”,我都会紧接着去追问“为什么?”
因为只有你知道了这背后的原理,你做出的回答才会被认为是正确的。
这个原理是如此的重要,以至于如果你不知道它,那么就几乎无法编写出正确的可并发执行的程序。如果你不知道此原理,那么即使你写的并发程序看起来可以正确地运行,那也肯定是运气好而已。
在此我只能用卧槽...
怎样才能让主 goroutine 等待其他 goroutine?
一旦主 goroutine 中的代码执行完毕,当前的 Go 程序就会结束运行,无论其他的 goroutine 是否已经在运行了。
那么,怎样才能做到等其他的 goroutine 运行完毕之后,再让主 goroutine 结束运行呢?
其实有很多办法可以做到这一点。其中,最简单粗暴的办法就是让主 goroutine“小睡”一会儿
fori:=0;i<10;i++{
gofunc(){
fmt.Println(i)
}()
}
time.Sleep(time.Millisecond*500)
在for语句的后边,调用了time包的Sleep函数,并把time.Millisecond * 500的结果作为参数值传给了它。
time.Sleep函数的功能就是让当前的goroutine(在这里就是主 goroutine)暂停运行一段时间,直到到达指定的恢复运行时间。
我们可以把一个相对的时间传给该函数,就像我在这里传入的“500 毫秒”那样。time.Sleep函数会在被调用时用当前的绝对时间,再加上相对时间计算出在未来的恢复运行时间。显然,一旦到达恢复运行时间,当前的 goroutine 就会从“睡眠”中醒来,并开始继续执行后边的代码。
这个办法是可行的,只要“睡眠”的时间不要太短就好。不过,问题恰恰就在这里,我们让主 goroutine“睡眠”多长时间才是合适的呢?如果“睡眠”太短,则很可能不足以让其他的 goroutine 运行完毕,而若“睡眠”太长则纯属浪费时间,这个时间就太难把握了。
一般在开发代码写
sleep是要挨打的
既然不容易预估时间,那我们就让其他的 goroutine 在运行完毕的时候告诉我们好了.
万金油的办法:如果两端的问题解决不了, 就加一个中间件
不知道是否想到Channel通道了
我们先创建一个通道,它的长度应该与我们手动启用的 goroutine 的数量一致。在每个手动启用的 goroutine 即将运行完毕的时候,我们都要向该通道发送一个值。
注意,这些发送表达式应该被放在它们的go函数体的最后面。对应的,我们还需要在main函数的最后从通道接收元素值,接收的次数也应该与手动启用的 goroutine 的数量保持一致。
funcmain(){
num:=10
sign:=make(chanstruct{},num)
fori:=0;i<num;i++{
gofunc(){
fmt.Println(i)
sign<-struct{}{}
}()
}
//办法1。
//time.Sleep(time.Millisecond*500)
//办法2。
forj:=0;j<num;j++{
<-sign
}
}
其中有一个细节需要注意。在声明通道sign的时候是以chan struct{}作为其类型的。其中的类型字面量struct{}有些类似于空接口类型interface{},它代表了既不包含任何字段也不拥有任何方法的空结构体类型。
注意,struct{}类型值的表示法只有一个,即:struct{}{}。并且,它占用的内存空间是0字节。确切地说,这个
值在整个 Go 程序中永远都只会存在一份。虽然我们可以无数次地使用这个值字面量,但是用到的却都是同一个值。
当我们仅仅把通道当作传递某种简单信号的介质的时候,用struct{}作为其元素类型是再好不过的了
有没有比使用通道更好的方法?
标准库中的代码包sync,sync.WaitGroup类型,是更好的办法
运行结果是不确定的:
7
10
2
10
10
10
10
10
10
10
既没有按顺序运行goroutine,也没有按我们期待的值进行输出
怎样让我们启用的多个 goroutine 按照既定的顺序运行?
怎样做到让从0到9这几个整数按照自然数的顺序打印出来?
你可别告诉我,不用goroutine就行了...
首先,我们需要稍微改造一下for语句中的那个go函数,要让它接受一个int类型的参数,并在调用它的时候把变量i的值传进去。为了不改动这个go函数中的其他代码,我们可以把它的这个参数也命名为i。
其实编辑器已经帮你提示了,go 语句的这个参数问题:
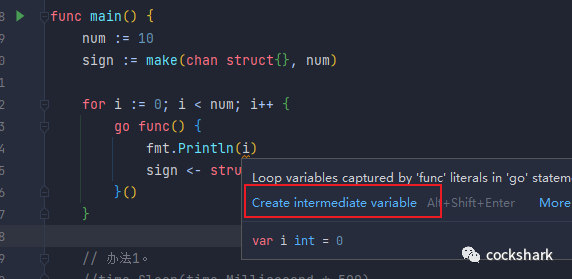
当然我们不按照编辑器提示的去增加一个参数短声明,我们让这个go语句增加一个参数:
fori:=0;i<10;i++{
gofunc(iint){
fmt.Println(i)
}(i)
}
只有这样,Go 语言才能保证每个 goroutine 都可以拿到一个唯一的整数。其原因与go函数的执行时机有关。
在go语句被执行时,我们传给go函数的参数i会先被求值,如此就得到了当次迭代的序号。之后,无论go函数会在什么时候执行,这个参数值都不会变。也就是说,go函数中调用的fmt.Println函数打印的一定会是那个当次迭代的序号。
我们在着手改造for语句中的go函数:
fori:=uint32(0);i<10;i++{
gofunc(iuint32){
fn:=func(){
fmt.Println(i)
}
trigger(i,fn)
}(i)
}
我在go函数中先声明了一个匿名的函数,并把它赋给了变量fn。这个匿名函数做的事情很简单,只是调用fmt.Println函数以打印go函数的参数i的值。
在这之后,我调用了一个名叫trigger的
函数,并把go函数的参数i和刚刚声明的变量fn作为参数传给了它。注意,for语句声明的局部变量i和go函数的参数i的类型都变了,都由int变为了uint32。至于为什么,一会儿再说。
再来说trigger函数。该函数接受两个参数,一个是uint32类型的参数i, 另一个是func()类型的参数fn。你应该记得,func()代表的是既无参数声明也无结果声明的函数类型。
trigger:=func(iuint32,fnfunc()){
for{
ifn:=atomic.LoadUint32(&count);n==i{
fn()
atomic.AddUint32(&count,1)
break
}
time.Sleep(time.Nanosecond)
}
}
trigger函数会不断地获取一个名叫count的变量的值,并判断该值是否与参数i的值相同。如果相同,那么就立即调用fn代表的函数,然后把count变量的值加1,最后显式地退出当前的循环。否则,我们就先让当前的 goroutine“睡眠”一个纳秒再进入下一个迭代。
注意,我操作变量count的时候使用的都是原子操作。这是由于trigger函数会被多个 goroutine 并发地调用,所以它用到的非本地变量count,就被多个用户级线程共用了。因此,对它的操作就产生了竞态条件(race condition),破坏了程序的并发安全性。
所以,我们总是应该对这样的操作加以保护,在
sync/atomic包中声明了很多用于原子操作的函数。
另外,由于我选用的原子操作函数对被操作的数值的类型有约束,所以我才对count以及相关的变量和参数的类型进行了统一的变更(由int变为了uint32)。
纵观count变量、trigger函数以及改造后的for语句和go函数,我要做的是,让count变量成为一个信号,它的值总是下一个可以调用打印函数的go函数的序号。
这个序号其实就是启用 goroutine 时,那个当次迭代的序号。也正因为如此,go函数实际的执行顺序才会与go语句的执行顺序完全一致。此外,这里的trigger函数实现了一种自旋(spinning)。除非发现条件已满足,否则它会不断地进行检查。
最后要说的是,因为我依然想让主 goroutine 最后一个运行完毕,所以还需要加一行代码。不过既然有了trigger函数,我就没有再使用通道。
trigger(10,func(){})
调用trigger函数完全可以达到相同的效果。由于当所有我手动启用的 goroutine 都运行完毕之后,count的值一定会是10,所以我就把10作为了第一个参数值。又由于我并不想打印这个10,所以我把一个什么都不做的函数作为了第二个参数值。
coding:
funcmain(){
varcountuint32
trigger:=func(iuint32,fnfunc()){
for{
ifn:=atomic.LoadUint32(&count);n==i{
fn()
atomic.AddUint32(&count,1)
break
}
time.Sleep(time.Nanosecond)
}
}
fori:=uint32(0);i<10;i++{
gofunc(iuint32){
fn:=func(){
fmt.Println(i)
}
trigger(i,fn)
}(i)
}
trigger(10,func(){})
}
通过上述的改造,我使得异步发起的go函数得到了同步地(或者说按照既定顺序地)执行。
上述代码:是让各个go函数(确切地说,是它们调用的trigger函数)自行地检查所需条件,然后再在条件允许的情况下打印数字。这也叫“自旋”。
总结
当我们想让运行结果更加可控的时候,应该怎样去做? 异步的回调? go函数的实际执行顺序往往与其所属的go语句的执行顺序(或者说 goroutine 的启用顺序)不同,而且默认情况下的执行顺序是不可预知的

点击下方卡片CloudNative NB
一起交流学习

▲点击上方卡片CloudNative NB,一起交流学习
请在gongzhong号后台




![[视频教程] golang 入门到精通](https://static.kouhao8.com/sucaidashi/xkbb/e842684397e882f374ce618ef1e850dd.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)







![[区块链技术] Golang公链开发实战课程 GO语言区块链开发技术课程 区块链开发技术全新实战视频教程](https://static.kouhao8.com/sucaidashi/xkbb/e818fa7fb61980136226423548dcfeba.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
相关资源