

Go 内存管理概述
发布于 2021-11-18 17:25 ,所属分类:软件编程学习资料
关注微信公众号《云原生CTO》更多云原生干货等你来探索
专注于云原生技术分享
提供优质云原生开发视频技术培训
面试技巧,及技术疑难问题解答

云原生技术分享不仅仅局限于Go、Rust、Python、Istio、containerd、CoreDNS、Envoy、etcd、Fluentd、Harbor、Helm、Jaeger、Kubernetes、OpenPolicyAgent、Prometheus、Rook、TiKV、TUF、Vitess、Argo、Buildpacks、CloudEvents、CNI、Contour、Cortex、CRI-O、Falco、Flux、gRPC、KubeEdge、Linkerd、NATS、Notary、OpenTracing、OperatorFramework、SPIFFE、SPIRE和Thanos等


Go 内存管理概述
内存管理
当程序运行时,它们将对象写入内存。在某些时候,当不再需要这些对象时,应该删除它们。这个过程称为内存管理。
本文旨在概述内存管理,然后深入探讨如何使用垃圾收集器在 Go 中实现这一点。多年来,Go 的内存管理发生了许多变化,并且很可能在未来看到更多。如果您正在阅读本文并且您使用的是 1.16 之后的 Go 版本,那么其中一些信息可能已经过时。
手动内存管理
在像C这样的语言中,程序员将调用malloc或calloc这样的函数来将对象写入内存。这些函数返回一个指向该对象在堆内存中的位置的指针。当不再需要此对象时,程序员调用free函数再次使用此内存块。这种内存管理方法被称为显式回收,非常强大。它使程序员能够更好地控制正在使用的内存,从而允许一些类型的更容易的优化,特别是在低内存环境中。然而,它会导致两种类型的编程错误。
一提前调用free,这会创建一个悬空指针。悬空指针是指不再指向内存中的有效对象的指针。这很糟糕,因为程序期望一个定义的值存在于指针上。当这个指针稍后被访问时,无法保证在内存中该位置存在什么值。可能什么都没有,或者完全有其他价值。第二,根本无法释放内存。如果程序员忘记释放一个对象,随着越来越多的对象填满内存,他们可能会面临内存泄漏。如果程序耗尽内存,这可能会导致程序减慢或崩溃。当必须显式管理内存时,程序中可能会引入不可预测的错误。自动内存管理
这就是为什么像Go这样的语言提供自动动态内存管理,或者更简单地说,垃圾收集。具有垃圾收集功能的语言提供如下好处:
增加安全 更好的跨操作系统的可移植性 更少的代码编写 代码的运行时验证 数组的边界检查 垃圾收集有性能开销,但并不像通常假设的那么多。这样做的代价是程序员可以专注于他们程序的业务逻辑,并确保它符合目的,而不是担心内存管理。
运行中的程序将对象存储在两个内存位置:堆和堆栈。垃圾收集操作的是堆,而不是堆栈。堆栈是存储函数值的LIFO数据结构。从函数中调用另一个函数将一个新帧推入堆栈,堆栈将包含该函数的值,以此类推。当被调用的函数返回时,它的堆栈帧将从堆栈中弹出。在调试一个崩溃的程序时,您可能会熟悉堆栈。大多数语言编译器都会返回一个堆栈跟踪来帮助调试,它会显示在此之前被调用的函数
相反,堆包含函数外部引用的值。例如,在程序开始时静态定义的常量,或者更复杂的对象,比如Go结构。当程序员定义一个放在堆上的对象时,将分配所需的内存量,并返回一个指向该对象的指针。堆是一个图形,其中的对象表示为节点,这些节点在代码中或由堆中的其他对象引用。当程序运行时,堆将随着对象的添加而继续增长,除非清理堆。
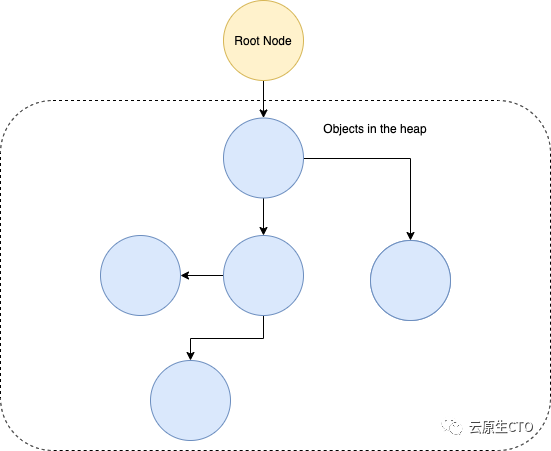
Go中的垃圾收集
Go更喜欢在堆栈上分配内存,所以大多数内存分配都会在堆栈上结束。这意味着Go每个goroutine都有一个堆栈,并且在可能的情况下,Go会将变量分配到这个堆栈中。Go编译器试图通过执行转义分析来验证一个对象是否“转义”了函数,从而证明函数之外不需要一个变量。如果编译器可以确定一个变量的生命周期,那么它将被分配给一个堆栈。但是,如果变量的生存期不清楚,那么它将被分配到堆上。通常,如果一个Go程序有一个指向对象的指针,那么该对象就会被存储在堆中。看看下面的示例代码:
typemyStructstruct{
valueint
}
vartestStruct=myStruct{value:0}
funcaddTwoNumbers(aint,bint)int{
returna+b
}
funcmyFunction(){
testVar1:=123
testVar2:=456
testStruct.value=addTwoNumbers(testVar1,testVar2)
}
funcsomeOtherFunction(){
//someothercode
myFunction()
//somemorecode
}
对于本例的目的,让我们假设这是一个正在运行的程序的一部分,因为如果这是整个程序,Go编译器会通过将变量分配到堆栈中来优化它。当程序运行时:
testStruct被定义并放在堆中一个可用的内存块中。在执行函数时执行并分配给 myFunction一个堆栈。testVar1和testVar2都存储在这个堆栈上。当 addtwonnumbers被调用时,一个带有两个函数参数的新堆栈帧被推送到堆栈上。当 addtwonnumbers完成执行时,它的结果返回给myFunction,并且addtwonnumbers的堆栈帧将弹出堆栈,因为它不再需要。指向 testStruct的指针跟随到堆上包含它的位置,并更新值字段。myFunction退出,为它创建的堆栈被清理。testStruct的值一直在堆上,直到垃圾收集发生。
testStruct现在在堆上,如果没有分析,Go运行时不知道是否还需要它。为了做到这一点,Go依赖于一个垃圾收集器。垃圾收集器有两个关键部分:突变体和收集器。收集器执行垃圾收集逻辑并找到应该释放内存的对象。mutator执行应用程序代码并将新对象分配给堆。它还在程序运行时更新堆上的现有对象,这包括使一些不再需要的对象不可访问。
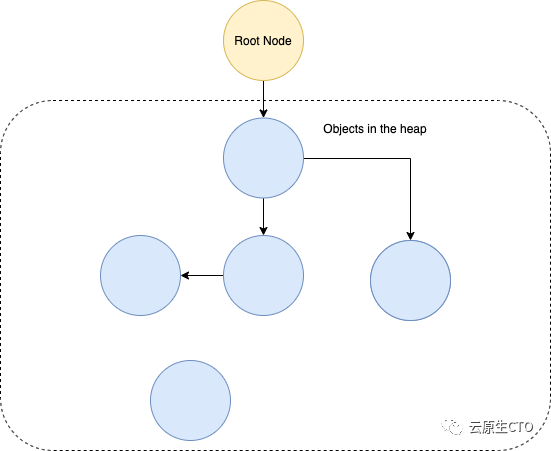
Go垃圾回收器的实现
Go的垃圾收集器是一个非分代并发、三色标记和扫描垃圾收集器。让我们分解这些项。
分代假设假设短期对象(如临时变量)最常被回收。因此,分代垃圾收集器最近分配的对象。然而,正如前面提到的,编译器优化允许Go编译器将具有已知生存期的对象分配给堆栈。这意味着堆上的对象会更少,因此垃圾收集的对象也会更少。这意味着在Go中不需要分代垃圾收集器。因此,Go使用非代际垃圾收集器。并发意味着收集器与可变线程同时运行。因此,Go使用非分代并发垃圾收集器。标记和清除是垃圾收集器的类型,三色是用来实现这一点的算法
标记和清除垃圾收集器有两个阶段,不出所料,即标记和清除。在标记阶段,收集器遍历堆并标记不再需要的对象。后续扫描阶段将删除这些对象。标记和扫描是一种间接算法,因为它标记活动对象,并删除其他所有东西。
Go用几个步骤实现这个:
Go让所有goroutine通过一个叫做stop the world的进程达到垃圾收集的安全点。这将暂时停止程序的运行,并打开写屏障以维护堆上的数据完整性。这通过允许goroutine和收集器同时运行来实现并发。
一旦所有goroutine都打开了写屏障,Go运行时就会启动世界并让工作人员执行垃圾收集工作。
标记是用三色算法实现的。当标记开始时,除了灰色的根对象外,所有对象都是白色的。根是所有其他堆对象都来自的对象,并作为运行程序的一部分实例化。垃圾收集器通过扫描堆栈、全局变量和堆指针开始标记,以了解正在使用的内容。当扫描一个堆栈时,工作人员停止goroutine,并通过从根向下遍历将所有找到的对象标记为灰色。然后它重新开始gorroutine。
灰色的对象然后排队变成黑色,这表明他们仍然在使用。一旦所有灰色对象都变成黑色,收集器将再次停止世界并清除所有不再需要的白色节点。程序现在可以继续运行,直到它需要再次清理更多内存。
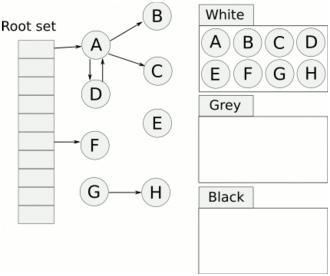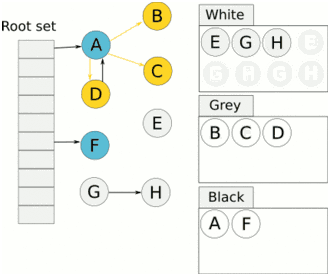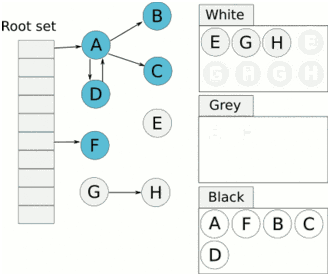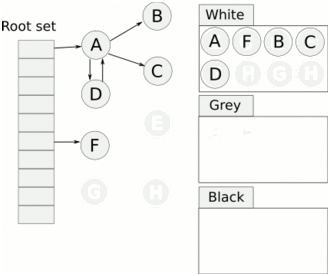
一旦程序按照所使用的内存比例分配了额外的内存,这个进程就会再次启动。GOGC 环境变量决定了这一点,并且默认设置为100。Go的源代码是这样描述的:
如果GOGC=100并且我们使用4M,当我们到达8M时,我们将再次GC(这个标记在next_gc变量中跟踪)。这使得GC成本与分配成本成线性比例。调整GOGC只是改变了线性常数(以及使用的额外内存量)。
Go的垃圾收集器通过将内存管理抽象到运行时中来提高您的效率,这也是使Go性能如此优异的原因之一。Go内置了一些工具,允许您优化程序中垃圾收集的发生方式,如果您感兴趣,可以研究这些工具。现在,我希望您对垃圾收集的工作原理以及它在Go中是如何实现的有了更多的了解。
进一步阅读[1]
参考资料
参考地址: https://medium.com/safetycultureengineering/an-overview-of-memory-management-in-go-9a72ec7c76a8













![[视频教程] go视频教程](https://static.kouhao8.com/sucaidashi/xkbb/2bbebabee3220bedaa5d641867ce9272.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)



![[视频教程] 尚硅谷 Go语言核心编程课程](https://static.kouhao8.com/sucaidashi/xkbb/5850341684cce785a9e4415a3755d65f.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
![[视频教程] 尚硅谷 Go语言核心编程课程](https://static.kouhao8.com/sucaidashi/xkbb/f1d865b99f5d150a767ca3cc237e94c8.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)



相关资源