

C4.5/5.0的SPSS操作步骤
发布于 2021-04-26 03:46 ,所属分类:知识学习综合资讯

作者:余羿审稿:柏安之封面:吉江


本节我们主要介绍如何运用spss统计软件进行决策树分析,在spss statistics 中,只能选择ID3,CART及chaid 决策树,而在spss另一款专门用于机器学习建模的软件 spss modeler 中,我们可以建立C5.0决策树(C5.0算法的分类规则同C4.5,只是在执行效率和内存使用上有所改进,适用于大数据集)。
我们引用名为 DRUG1n 的数据文件,这是关于身患同一疾病的一组患者的数据。在治疗过程中,每位患者均对五种药物中的一种有明显反应。本案例是通过数据挖掘找出适用于今后患有此疾病的患者的药物。数据样本记录总共200条,拟按照训练集与测试集比例7:3划分,则约140个样本用于建模,70个样本用于测试模型的有消息。(为了防止过度拟合,在有监督机器学习中通常会对样本进行拆分,一般为7:3或4:3:3,在此我们使用7:3模式,实际数据分割时按随机种子的不同会有细微调整)
本次教程使用软件版本为 IBM SPSS Modeler18.0,鉴于平时使用spss modeler的同学相对较少,本篇将是多图小白教程,具体操作步骤如下:

一、数据导入
新建空白流,选择下方 “收藏夹”或“源”选项卡里面的“变量文件”节点,鼠标单击按住拖到空白处,然后,双击新添加的节点以打开其对话框。
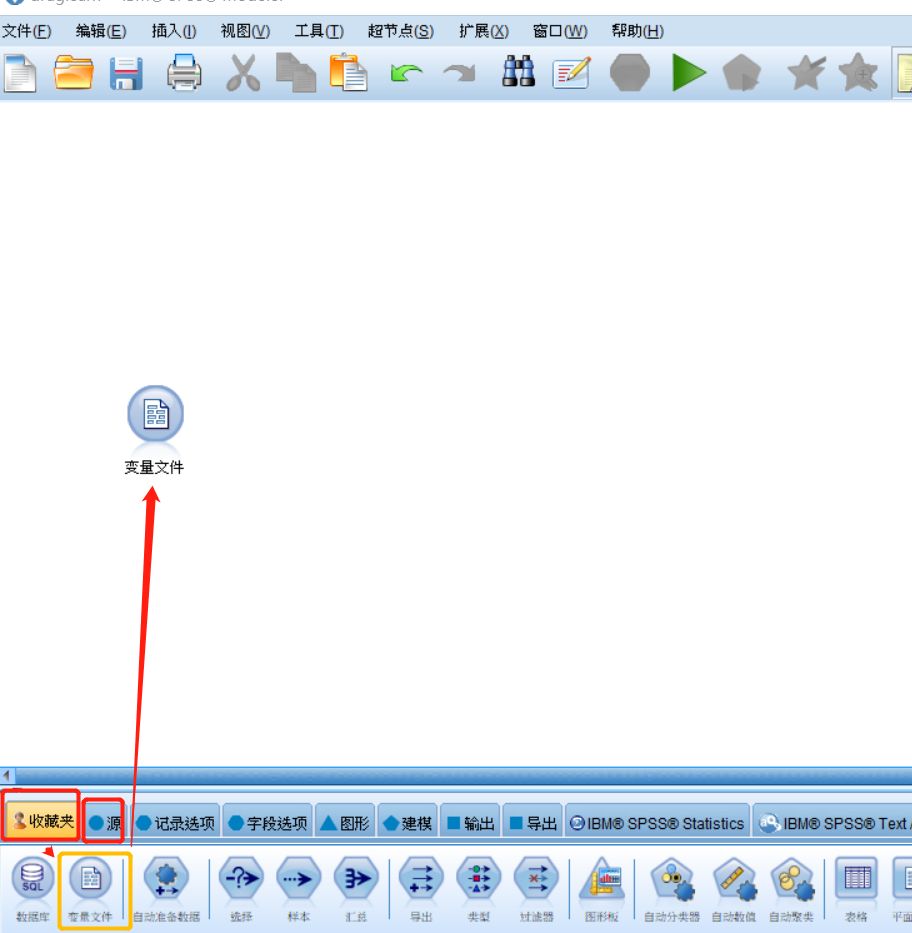
图一 新建节点
单击紧挨“文件”框右边以省略号“...”标记的按钮,浏览到您系统中的 IBM® SPSS® Modeler 安装目录。打开 Demos 目录,然后选择名为 DRUG1n 的文件。
确保选中了从文件读取字段名称,注意已加载此对话框中的字段和值。
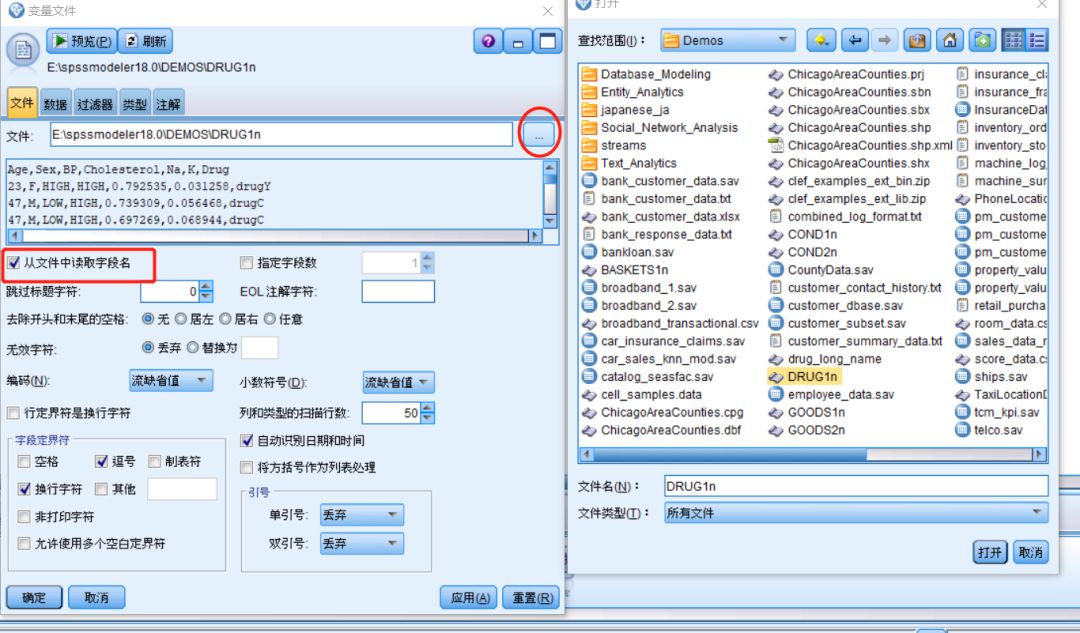
图二 导入文件
单击数据选项卡,覆盖和更改某个字段的存储。注意,存储不同于测量,即,数据字段的测量级别(或用途类型)。
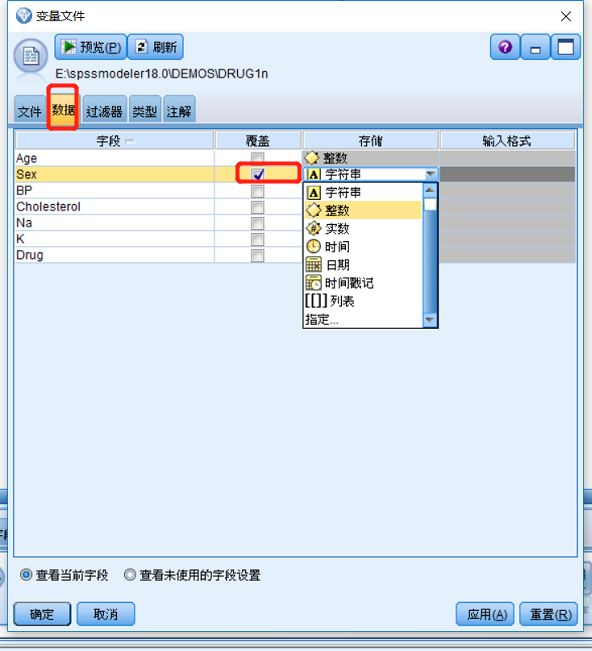
图三 导入文件设置
二、数据审核
先单击变量文件,再双击下方输出选项卡中的“数据审核”,画布上会出现与变量文件连接的“数据审核”节点
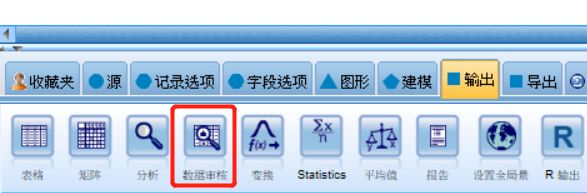
图四 增加数据审核节点
双击数据审核节点,弹出窗口中点击“运行”
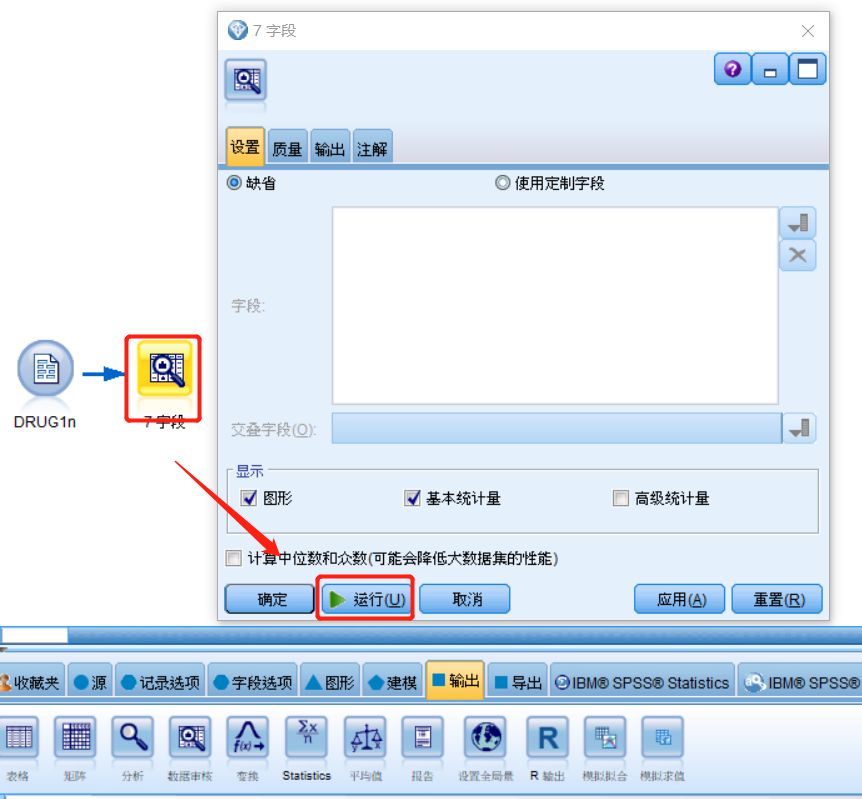
图五 数据审核
结果窗口包括对对各变量的描述性统计,以及对缺失值和离群点的审核
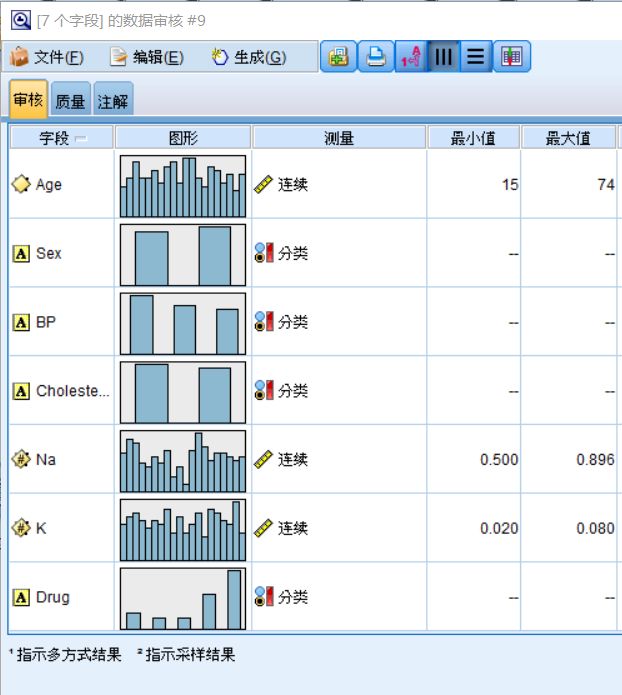
图六 描述性统计
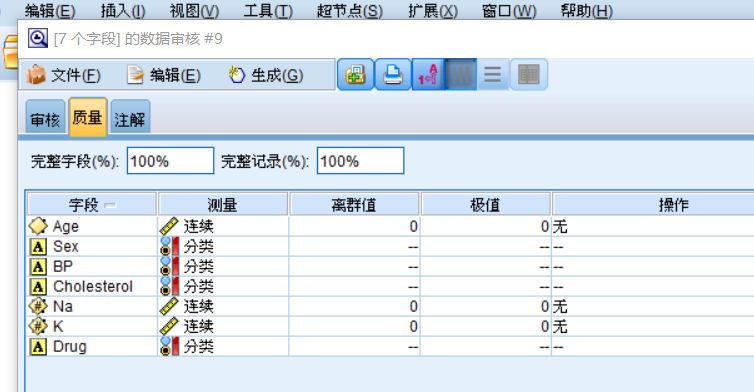
图七 离群点审核
三、数据分区
本次数据无离群点,下一步便是分割训练集和测试集
先点击变量文件节点,再在下方“字段选项”卡双击分区,生成“分区”节点
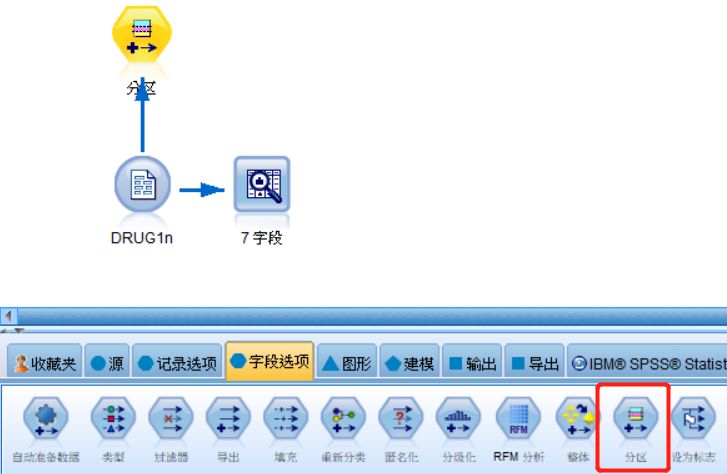
图八 增加数据分区节点
双击画布中的分区节点,在弹出的窗口中设置训练集和测试集的比例,设置完成后点击“确定”完成数据分割
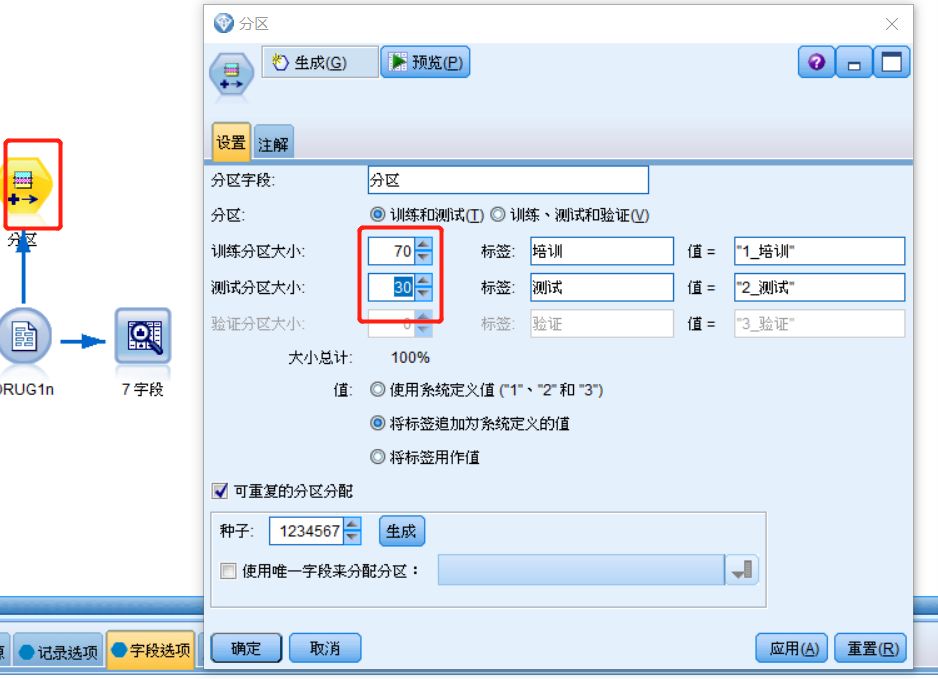
图九 数据分区
四、数据规整
双击下方“字段选项”选项卡中的“类型”,生成类型节点。
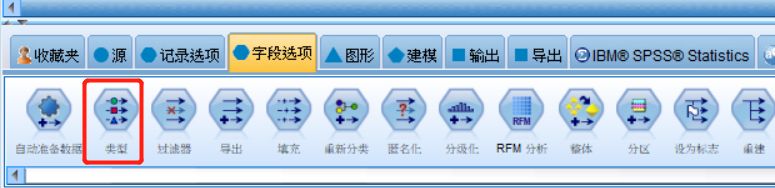
图十 添加类型节点
双击类型节点,弹出的窗口中“类型” 选项卡可帮助了解数据中的更多字段类型。还可以选择 读取值 来查看各个字段的实际值,而设置“角色”可以区分因变量与自变量,此处我们将将因变量的角色设置为“目标” 。
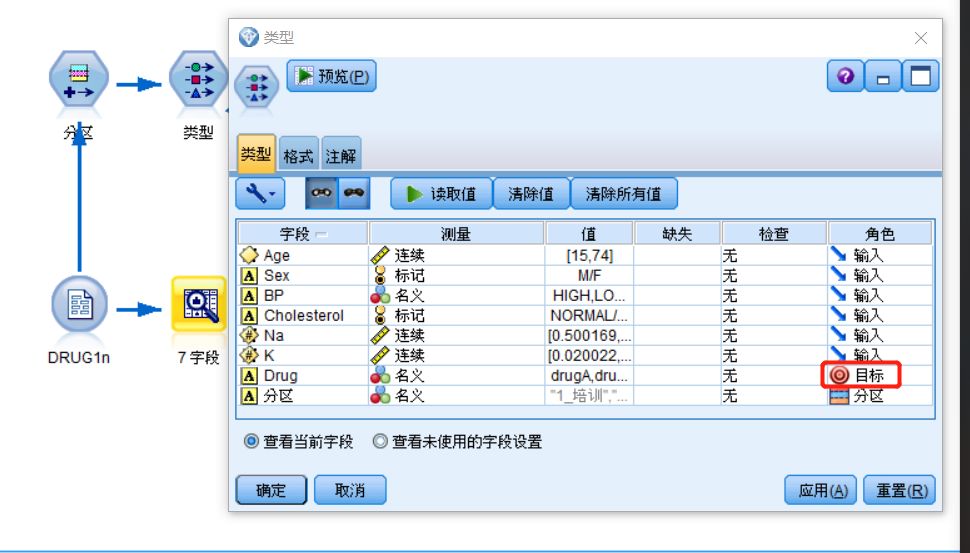
图十一 类型设置
五、决策树建模
终于到了正式建模阶段,双击下方建模选项卡中的C5.0,生成C5.0决策树建模节点
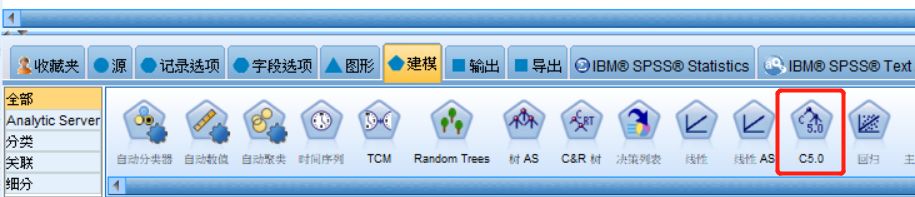
图十二 选择建模节点
双击C5.0建模节点在弹出窗口里可设置参数,如果要设置剪枝,选择专家模式,再进行相应参数设置,我们这里使用默认参数,参数完成后,点击下方“运行”
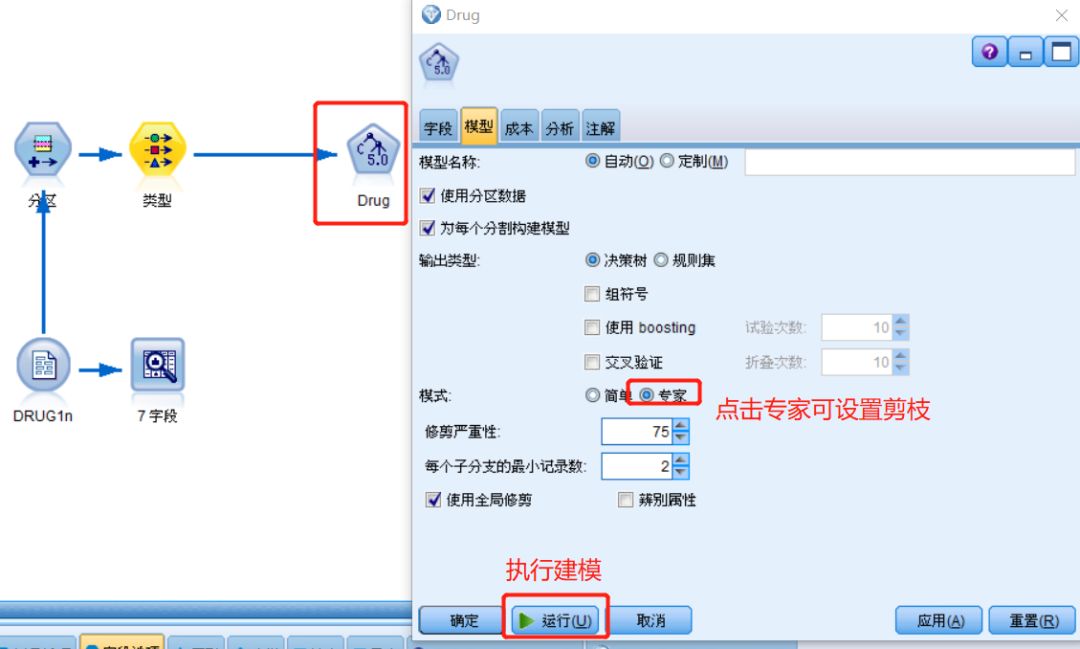
图十三 建模参数设置及执行
执行建模后,会生成具体的模型规则节点
图十四 规则节点
双击模型规则节点,出现的窗口中模型选项卡里是具体的规则和预测变量的重要性排序图
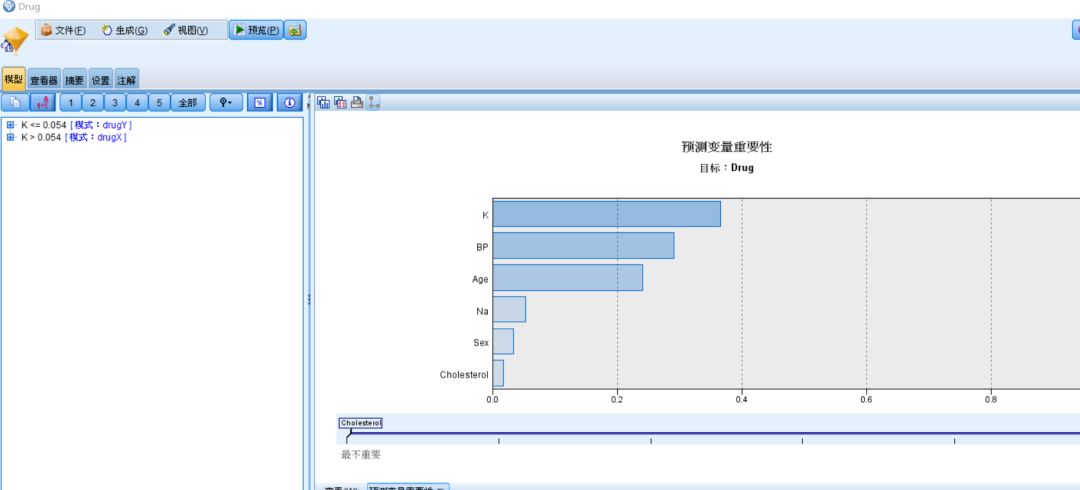
图十五 规则展示
规则一开始只显示第一层规则,单击规则前面的小+号可以查看具体细分规则
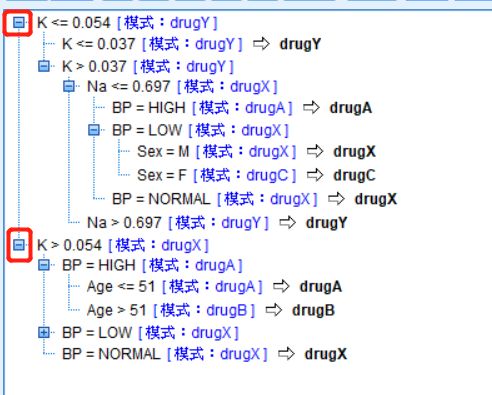
图十六 规则明细
点击“查看器”选项卡则可以看到具体的决策树图形
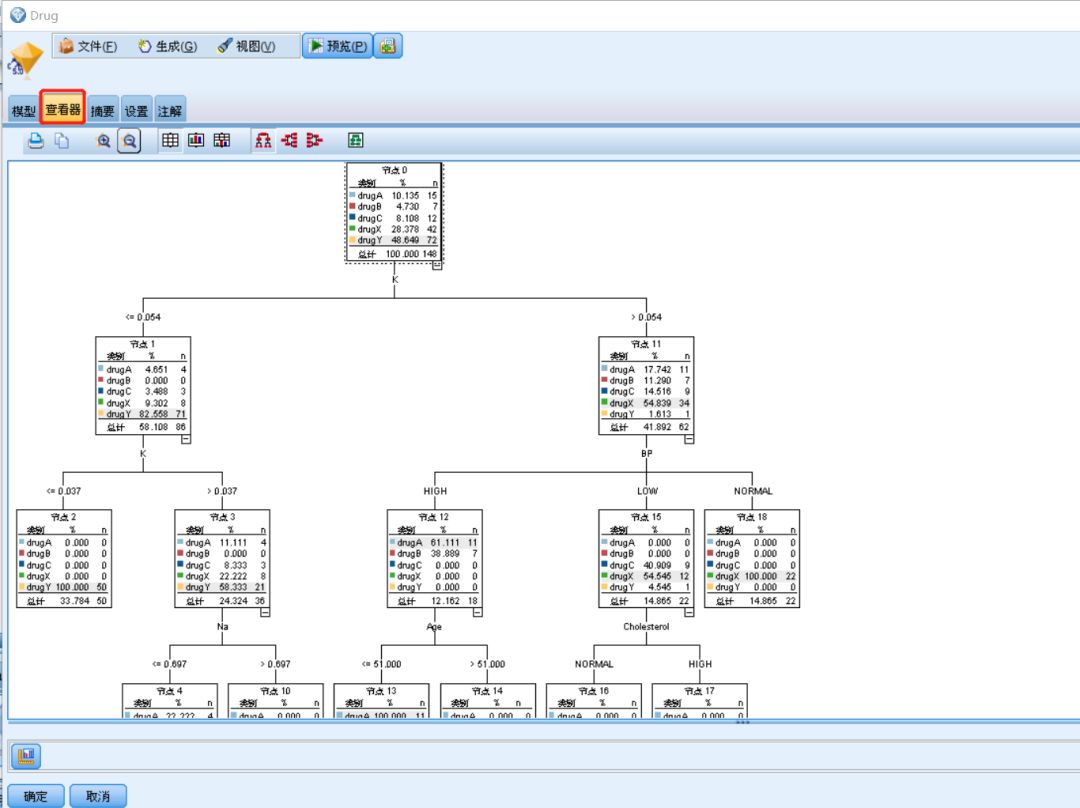
图十七 决策流程树图
六、模型评估
再双击下方“输出”选项卡中的“分析”,生成分析节点
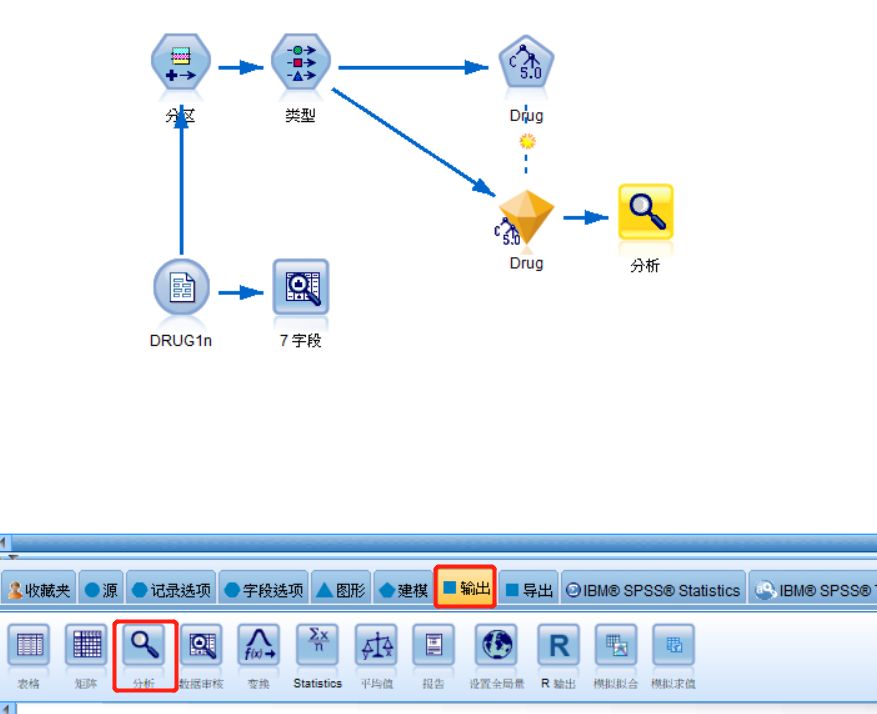
图十八 分析节点
双击分析节点,在弹出窗口中自行选择分析指标,然后点击下方“运行”
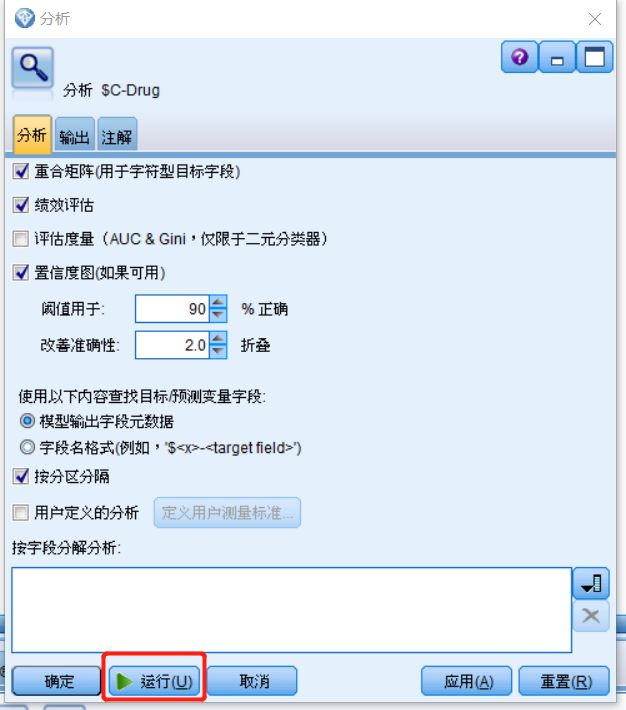
图十九 分析参数
结果窗口里便是模型准确性的评估
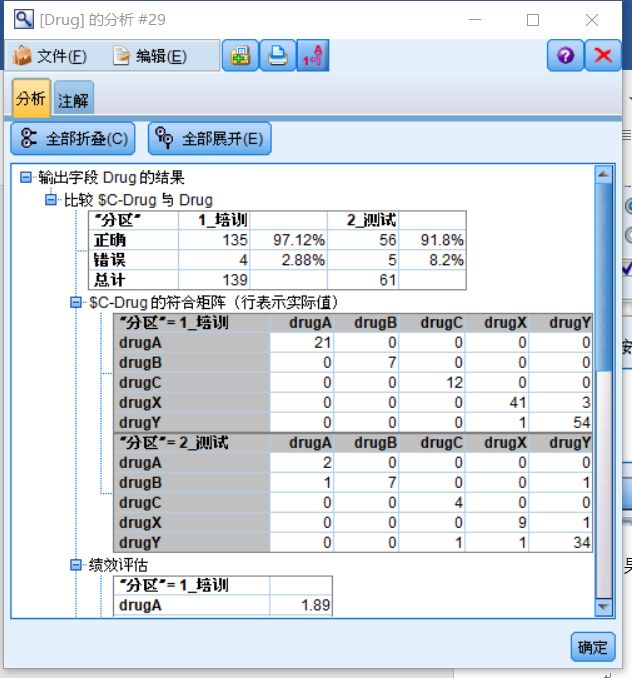
图二十 评估结果视图
至此,决策树流程操作便已结束

七、结果分析
表1、案例处理汇总
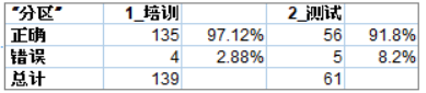
表一给出了数据集的划分情况,以及不同数据集中的预测准确率,可以看出无论训练集还是测试集预测准确率均在90%以上。
表2、预测变量重要性
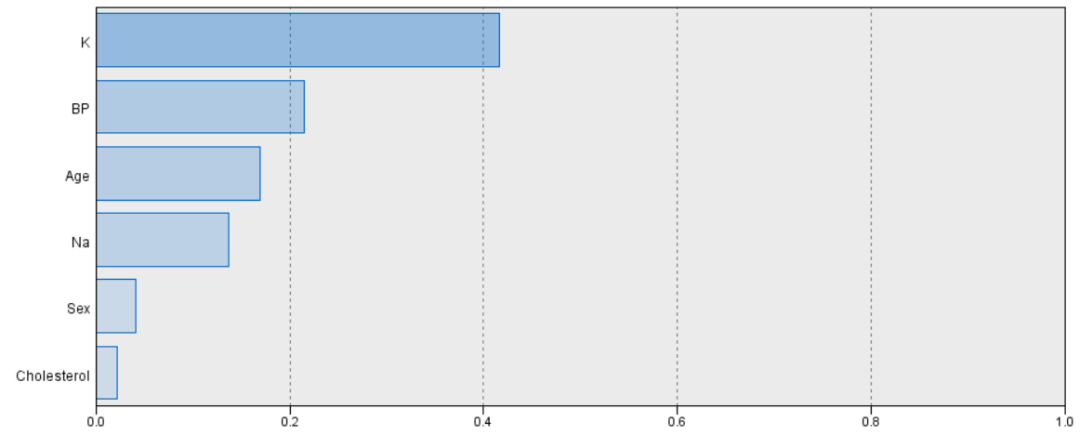
通过表2可看出重要性最强的特征为K,其次是BP和Ag,Cholesterol重要性最差。
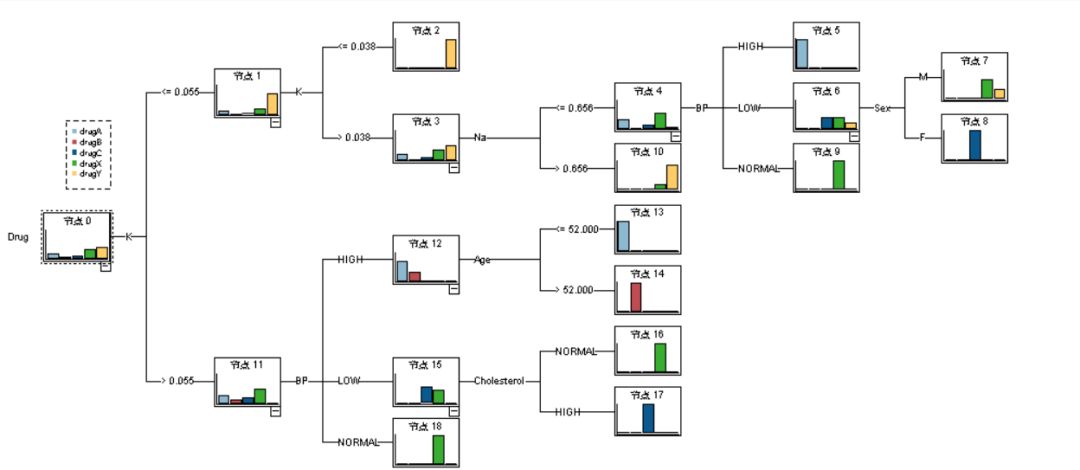
图二十 决策树具体分类树图
在图20中可看出具体决策流程和分类规则,重要性越强的特征处于越上游的分支节点。
gongzhong号,回复20190605即可获得原始数据哦~

















![[C语言] 猎豹网校 大家可以学的C语言 C语言学习视频教程](https://static.kouhao8.com/sucaidashi/xkbb/78fbbb5e62c6788c5d85a59af3843e03.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)




![[架构] 老孟学堂ThinkPHP5.0入门到精通视频教程 包含项目实战](https://static.kouhao8.com/sucaidashi/xkbb/665feb36903ba1bae0bebf0a380c737f.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

![[C语言] 分享自己收藏的18套嵌入式+C语言+C++视频教程 学好C语言看这里就够了](https://static.kouhao8.com/sucaidashi/xkbb/d5dd3afb5e3eb118e73400dda8792c48.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)



![[PC技术] 曹鹏SEO视频教程全解 53集详细学习步骤](https://static.kouhao8.com/sucaidashi/xkbb/fbf5e1469d3f87698963f073f74b692b.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)
相关资源