

奔跑吧!智能Monkey之Fastbot跨平台
发布于 2021-08-04 15:58 ,所属分类:知识学习综合资讯
1. 背景
近年来 AI+Test 相关的智能化测试技术,已经逐步成为国内·国际大型互联网公司和各大测试服务提供商的基础能力。其智能化包含测试代码的自动生成、大规模测试结果分析、自动化探索性测试、缺陷定位及修复等。相关公司、产品或服务比较有代表性的有:Test.AI、Applitool、Totoro、Eggplant、Appdiff 等。
其中,自动测试生成能力一直是工业界的热点。2019 年字节跳动 Quality Lab 在自动测试生成方面进行了比较深入的探索,并研发了针对 Android 的稳定性测试服务 Fastbot。Fastbot 的核心技术主要包括:
智能遍历:使用基于模型的测试生成(MBT),并提供多种算法策略,以获得较高的 Activity 覆盖率及问题发现能力; 多机协同:最高支持数百台长时间多机协同遍历,同一个目标彼此协作; 个性化的专家系统:业务方可以进行多种个性化配置,比如:限定测试在指定的 Activity 运行,屏蔽测试某些场景; 模型复用:利用历史测试经验数据学习改进当次测试策略; 复杂用例生成:对人工用例进行模仿学习,遍历过程中混合复杂用例的组合生成; 精准定向:根据代码调用链变更自动生成针对变更场景的定向测试。
与此同时,根据行业跨平台调研,iOS 市场占有率一直较高,特别是高端消费用户普遍用 iPhone 设备追求更好的性能体验,同时也对应用稳定性有较高要求。但目前了解到市场中因缺少 iOS 稳定性测试工具,iOS 产品的稳定性、回归等测试大都采用人工验证的方式,测试的效率和产出相对都比较低,同时面临产品多样化、复杂化、产品线迅速扩张的情况下质量保障的人力投入成本巨大。为缓解这一情况,急迫需要一款针对 iOS 端应用稳定性测试服务,以超低接入成本、无人值守运行的方式在公司产品线测试左移阶段部署使用。同时为了将 Fastbot 的智能化能力辐射到其他平台,字节跳动 Quality Lab 在 2020 年初开始逐步展开了对 iOS 端稳定性测试服务的研发工作,首先有两个问题是值得思考的:
Android 的遍历算法是否可以跨平台通用? 是否有一种机器视觉通用跨平台页面识别方法?
这两个答案都是肯定的。
接下来,本文将重点介绍字节跳动自研的智能化测试系统 Fastbot 在跨平台方面的设计思路、技术演进及应用。
2. 测试生成
2.1 自动测试生成简介
自动测试生成 ATG(Automated Testing Generation)技术,也叫 AIG(Automated Input Generation)技术。传统的自动化方式,比如录制与回放(Record & Replay),依赖于测试人员编写测试脚本。同时,跟随着测试需求的改变,测试人员需要耗费一定的时间维护和调整相应的测试脚本。与录制回放的方式相比,将测试活动依赖的通用服务进行抽象,依靠自动的方式生成测试活动需要的操作,能较大程度减少测试脚本的编写与维护工作量。
| 人力需求 | 脚本工作量 | 可复用程度 | 执行效率 | 通用型 | |
|---|---|---|---|---|---|
| 录制与回放 | 多 | 多 | 中等 | 低 | Apk 有关,低 |
| 原生 Monkey | 少 | 少 | 少 | 高 | Android 自带,高 |
| 测试生成 | 少 | 少 | 少 | 高 | Apk 无关,高 |
目前,典型的 ATG 技术有:
程序分析;(Code-Based Testing); 基于模型的测试生成(Model-Based-Testing); 组合测试(Combinatorial Testing); 基于搜索的测试生成(Search-Based-Testing), Facebook 的 Sapienz; 自适应随机测试(Adaptive Random Testing)。
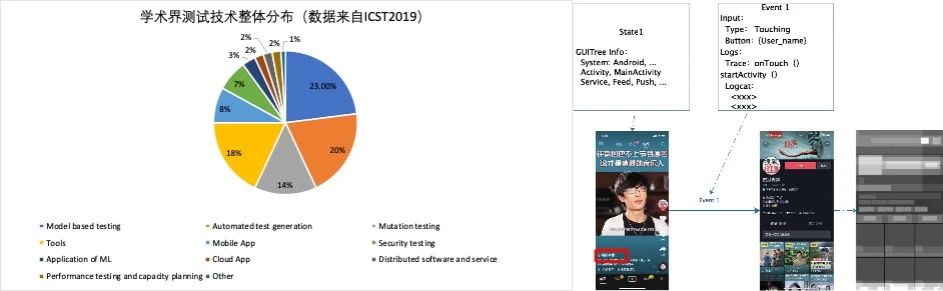
图 1 ATG 技术简介
它们核心的逻辑聚焦在“如何生成”测试逻辑。以 MBT 为例,GUI 测试(客户端测试)过程中的某个页面,可以被定义为一个状态(State),利用该页面对应的 GUI 控件树,我们可以提取其中更有意义的操作,比如从 State1 通过 Event1 可以到达 State3,从 State2 通过 Event2 可以到达 State1。这样,测试生成的问题转化成对有向图的遍历问题。像 Monkey 之类的随机测试工具,由于缺少对于 Log 的更高层面的表述,常让开发者对其有担忧:
由 Monkey 生成的测试序列不容易以文档的形式描述用例; 比较难复现 Bug,缺少复现的详细步骤。
2.2 自动化测试工具
针对 App 的 ATG 技术主要包括两大类。
其一是基于代码层面的白盒自动化测试工具。这种方法通常需要提前获取 App 源码,对其分析后产生控制流图,并在此基础上通过测试生成手段产生测试用例。白盒测试的方法虽然更加精确,但限制较多,对于无法获取源码的 App 无法有效的测试。另外,为达到较高的代码覆盖率,会不可避免的产生过多的测试用例。
其二,我们也可以基于 App 中的 GUI 信息进行黑盒测试。这种测试类型无需获取 App 源码,我们只需要在测试过程中监听手机页面的 UI 信息,完成动作注入,即可实现持续的交互型测试。
当下流行的其他黑盒自动化测试工具包括:
Facebook 研发的 Sapienz,它使用遗传算法和基于搜索的方式来生成测试用例; 佐治亚理工大学开发的 Dynodroid,它把 App 看作一系列可执行的动作,并依次产生测试序列; EHBDroid(偏灰盒)绕过 UI 层面,用静态加动态的方法直接通过 event handler callback 来触发事件 ; Stoat 先构建 State-Action 的概率图模型,再通过 MCMC sampling 的方法优化这个模型以达到对 App 的最优覆盖; APE 提出了一种动态调整页面 State 抽象的方法,能根据不同的 App 情况选择合适的抽象粒度; TimeMachine 在模拟器上运行,通过在关键测试环节 save-load 模拟器状态,实现测试优化和精确回放; Q-Testing 预训练了一个页面抽象的机器学习模型,再通过好奇心驱动的强化学习方法做测试探索; ComboDroid 对人工用例进行了抽象和扩展,识别出 State 的连通关系并生成更丰富的测试用例; 以及上文提到的 Android 自带的随机测试工具 Monkey 等。
此外,北大研发的 Droidbot 和 Humanoid 工具也使用了基于模型的 GUI 测试,其中 Humanoid 以用户行为为基准进行模仿,而 Droidbot 则是将页面和动作抽象为图模型,通过传统的 DFS 和 BFS 算法进行图的遍历,以达到高覆盖率。
然而,在我们的测试过程中发现,传统的图遍历算法在基于模型的 GUI 测试中效果不佳。原因在于:
图中存在大量的环路,使用基于 DFS 的算法极易陷入局部循环当中,只覆盖有限的页面而无法退出; 实际被测 App 基本都是动态且实时更新的,某些页面(如 Feed 页、搜索页等)存在严重的退出后无法重新到达的问题,简单的后退操作也无法保证能回到上一步的页面,下拉刷新等动作没有对应的后退操作等。
此外,上述方法都将 App 模型存储于客户端,由于手机设备内存及性能限制,模型大小将严重受限,测试无法长时间进行。而且,由于大量的 AB 实验利用了设备的机型、OS 版本等数据,每台设备上能够遍历到的 State 数量也不尽相同。
在 Android 上的 Fastbot 利用了更丰富的机型设备,借助手机农场(device farm)来共同构建 App 模型,以指导未来的测试任务;同时,我们也优化了传统的图搜索算法,转用启发式搜索,以期在更短时间内获得更高的测试覆盖率。
3. Fastbot 的设计原理
3.1 Fastbot-Android 的工作流程
如上所述,为了解决基于模型的 GUI 测试会受到手机端的内存大小和计算能力的限制,我们将消耗大量内存与计算资源的部分部署到云端,在客户端只保留 UI 信息监听和动作注入的功能。图 2 展示了客户端与服务端分离的工作方式。
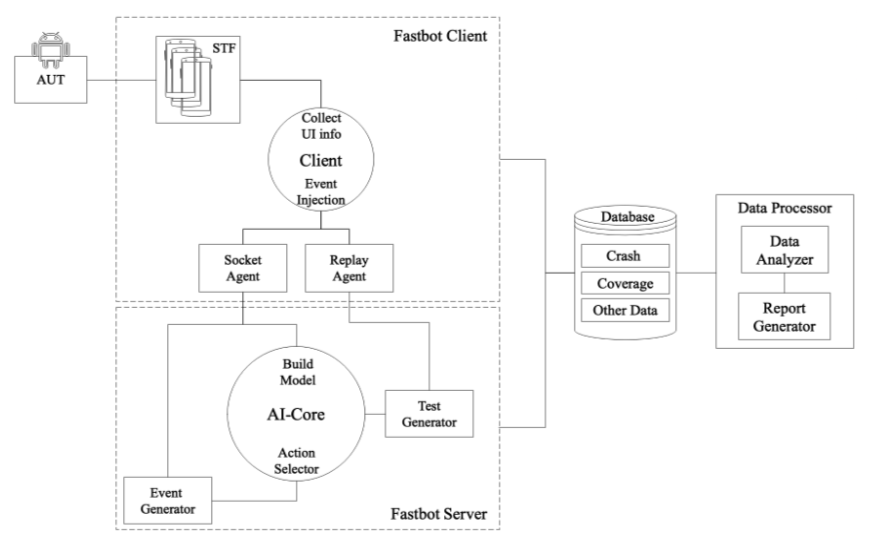
图 2 Fastbot 工作流程图
具体工作流程上,我们会在每个设备上运行一套轻量级的客户端驱动,其主要包括:监控页面 GUI 信息发送给服务端,以及接收服务端发送的动作并在设备上实现事件注入。与之对应的,在服务端也有代理 Agent。每个服务端 Agent 为一台设备负责,接收其页面信息,对其进行封装,产生 State 节点,服务端 Agent 会根据当前的 State 信息,根据分配好的指定算法,与任务模型交互做出动作决策,并将决策出的动作发送回给客户端 Agent。
3.2 Fastbot 的算法原理
3.2.1 基于状态的探索(Exploration)与利用(Exploitation)
在算法方面,我们将页面的 GUI 信息抽象成模型中的 State,将执行的动作抽象成模型中的 Action,通过 State 作为图的节点,Action 作为图的边,连接形成有向有环图模型。遍历决策想法上源于 Alphago 的蒙特卡洛搜索树的思想,此基础上我们也使用了其他强化学习的方法,设计了 N 步 Q-Learning 算法和基于页面变化程度的 reward function,为页面下每个 Action 计算出相应的 Q 值,基于 Q 值选取最优动作。
整个这个过程就类似我们在做一个地图探路的机器人。我们的目标是追求覆盖地图的所有路径,同时在时间有限的情况下,希望在已知信息下优先去走价值更高的路径。这里的价值实际是个比较广的概念,我们可以按自己的目标去定义价值。如果我们的目标是从 A 到 B,那么实际上我们可以学习出一条或几条固定的路径。这里需要理解另一个概念,如果我们的探路机器人到达一个新的路口,这个路口有 N 个分叉,如果这些分叉我们没有探索过,我们也就不知道这些分叉后续路的价值,所以也就无法做出对的决策了,所以我们需要对探索(Exploration)和利用(Exploitation)之间进行平衡,当我们探索过一条路径,同时也会将路径上看到的信息反向传播回去以此指导机器人记录这一整条链路上的价值,只有当探索足够充足利用才有价值(这里的利用是指做最优 Action)。另外如果我们对整个地图中的路做无穷次探索,那么最终各 Action 间 Q 值将恒定到一定的比例,这样对地图有足够多的信息,做出的决策才更准确;对于遍历亦是如此。
简单来说,遍历时选择当前 State 下对应 Value 最大的 Action。选择能够带来最大 Value 加成的 Action。比如下图 StateA 状态下,可以采取的 Action 有 3 个,但是 Action2 带来的 Value 最大,所以最终 Agent 进入 StateA 状态时,就会选择 Action2。(强调一点这里面的 Value 值,在强化学习训练开始时都是不知道的,我们一般都是设置为 0。然后让 Agent 不断去尝试各类 Action,不断与环境交互,不断获得 reward,然后根据我们计算 Value 的公式,不停地去更新 value,最终在训练 N 多轮以后,Value 值会趋于一个稳定的数字。才能得出特定 State 下,选择某个 Action,会得到怎样的 Value)
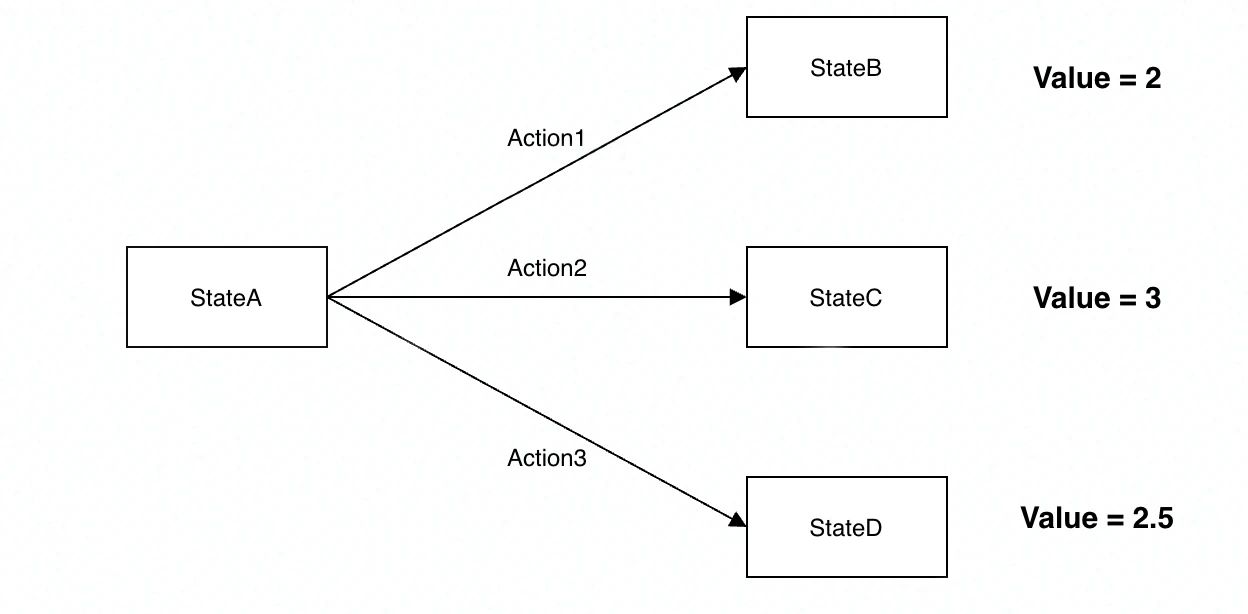
图 4 强化学习事件决策
强调一点这里面的 Value 并不仅是从当前 State 进入下一个 State,环境给的 reward。因为我们实际训练时既要当前的收益,也要长远的收益,所以这里面的 Value 是通过一个计算公式得出来的,而不仅仅是状态变更环境立即反馈的 reward。这个计算公式取决于用的是单步还是 N 步;而且这个 Value 是采样得到的,需要经历多轮迭代,loss 收敛后才能认为训练结束。
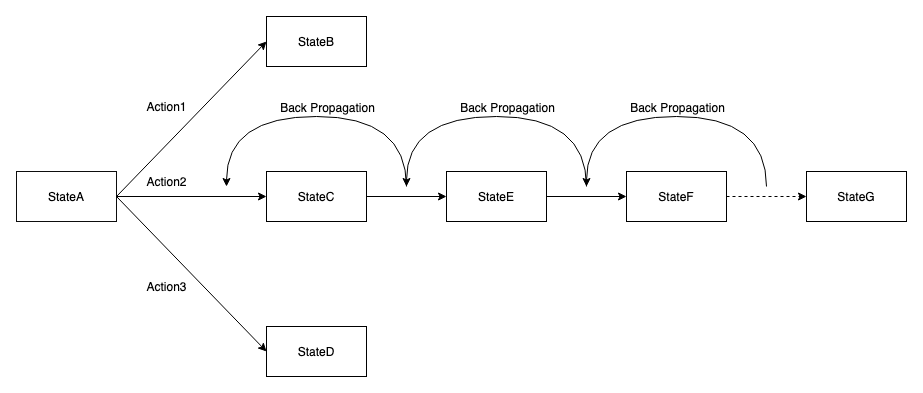
图 5 反向更新 Value
另一个问题,如上图 4StateA 的状态下,最开始 Action1&2&3 对应的 Value 都是 0,因为执行前我们根本不知道,初始值均为 0。如果第一次随机选择了 Action1,这时候 StateA 转化为了 StateB,得到了 Value=2,系统记录在 StateA 下选择 Action1 对应的 Value=2。如果下一次 Agent 又一次回到了 StateA,此时如果我们选择可以返回最大 Value 的 Action,那么一定还是选择 Action1。因为此时 StateA 下 Action2&3 对应的 Value 仍然为 0。Agent 根本没有尝试过 Action2&3 会带来怎样的 Value?
所以在结合强化学习遍历的时候,一开始会让遍历更偏向于探索 Explore,并不是哪一个 Action 带来的 Value 最大就执行该 Action,选择 Action 时具有一定的随机性(我们使用了一种基于访问次数叠加 Value 的 UCB 决策机制),目的是为了覆盖更多的 Action,尝试每一种可能性。等训练很多轮以后各种 State 下的各种 Action 基本尝试完以后,我们这时候会大幅降低探索的比例,尽量让遍历更偏向于利用 Exploit,哪一个 Action 返回的 Value 最大,就选择哪一个 Action。
3.2.2 奖励稀疏问题
算法上还有个难点是在遍历过程中奖励(reward)往往是十分稀疏的,最初我们 reward function 的设计是通过已覆盖 Activity 和控件个数的统计数据来计算,但遍历中后期这些指标基本上趋近于恒定了,reward 很难有明显的增长,于是对于后期基于这样奖励的学习效果就不够理想了。通过一些实验踩坑,我们选择使用好奇心强化学习的方法来解决奖励稀疏问题,同时结合自然语言处理对页面信息做特征抽象,在原有 reward function 基础上增加好奇心(Curiosity)的 reward,流程如下:

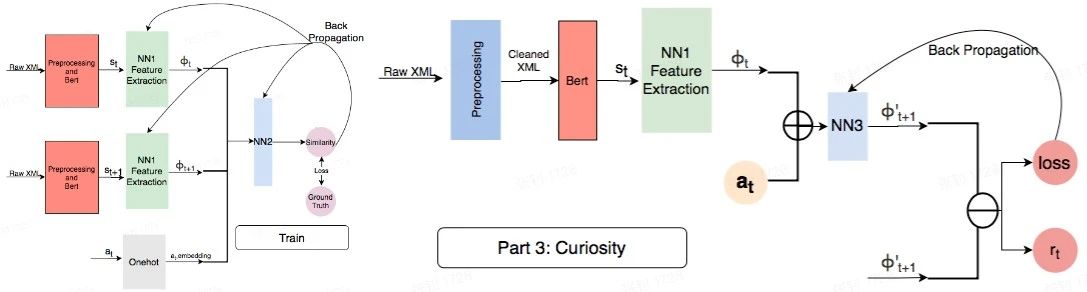
图 6 Curiosity Driven RL 流程图
这样 reward 计算更新为:
这样就实现了对任意一组状态动作对给予一个不同奖励值,而不是根据人为设置子目标来给予一个固定的奖励值。
同时我们做了几组消融实验,得到了以下的结论:reward 计算不添加 Curiosity(下图 7 c0 蓝线)和 reward 只通过 Curiosity 计算(c99 绿线)都比混合使用原 reward 叠加 Curiosity reward(c30 橘黄线)效果略差。从数据可见 Curiosity driven 引入对测试覆盖是有正向效果的,前期尤甚。
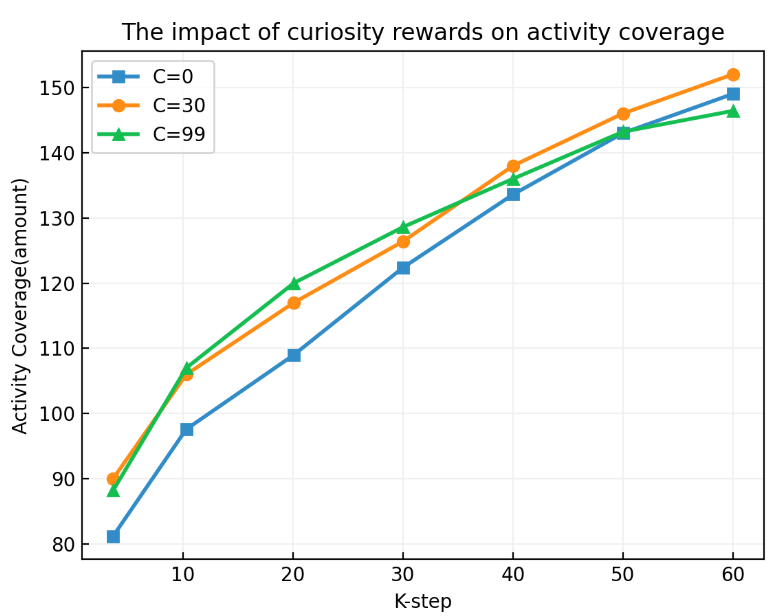
图 7 Curiosity Driven RL 消融实验
好奇心驱动总结起来就是“恰恰满足了强化学习需要基于时间上学习才有意义,好奇心加入了时间差异性因素”。
但这种技术并非完美。一个已知问题是:Agent 可能被环境中的随机元素或嘈杂元素吸引造成好奇心的扰动。这种情况被称为“白噪声”或“电视问题”,亦被称为“拖延”。
为说明这种情况,我们来想象一个 Agent,通过在迷宫中观察它看到的像素来学习如何在迷宫中探索到指定目标(蓝色的球)。

动画 1 探索迷宫
对下一个状态预测来引发 Agent 学习在迷宫中探索的好奇心。它会倾向于寻找迷宫中未被探索的区域,因为它有能力在探索充分的区域做出良好的预测(或者说,它无法在未探索的区域做出好的预测。)
假如现在在迷宫的墙上放置一个“电视”,快速连续地播放一个随机的动画。由于图像的随机来源,Agent 无法准确预测接下来会出现什么图像。预测模型将产生高损失,从而为 Agent 提供高“内在”奖励。最终结果是 Agent 倾向于停下看“电视”,而不是继续探索迷宫。

动画 2 卡死在电视机前
在环境中,当 Agent 面对“电视”,或随机噪声来源时,下一状态预测引起 Agent 好奇心最终导致 “拖延”。
遍历中亦可如此,是否存在“电视”完全取决于这个“像素”的精度定义是否合理。试想一个正在播放短视频的页面或是一直在轮播的广告页,Agent 站在原地瞪着会不会认为这是一个始终充满好奇的地方?
3.2.3 测试经验复用
考虑到每次遍历时间并非固定,不同 App 情况也不同,当遍历时间较短时训练就可能存在不充分的情况。所以我们将每次训练完的模型也进行持久化保存,在下次测试前会先加载上次的模型继续训练,这样“地图”也就越来越全了。同时我们将遍历的数据以“GUITree1,Action,GUITree2”结对形式存储到持久化 DB 库中,用于改进自然语言模型和好奇心模型。
从实际测试数据上看模型复用对测试覆盖率也有正向效果,如下图 8 图示,a、b 是字节两款不同类型的 App,经过多轮累积测试,单次同时长测试覆盖能力分别提升 17.9%,33.3%。
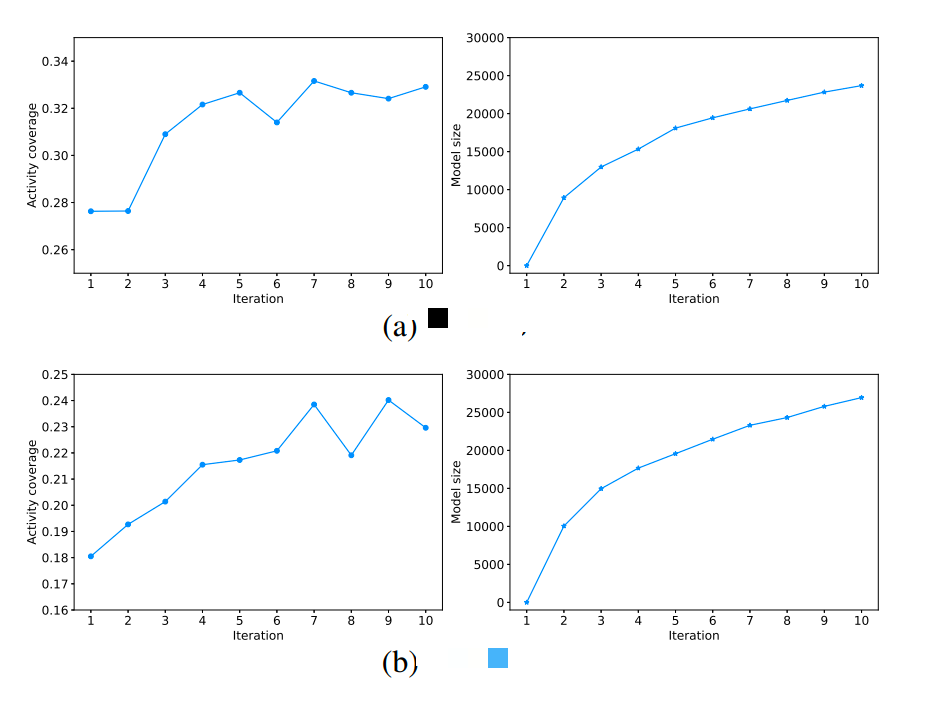
图 8 模型复用
为了验证工具的效果,我们将 Fastbot(Re)与其他几款同类 State of the art 测试工具做了数据对比实验,其中包括基于动态调整页面 State 抽象的 APE(A)以及基于抽样优化概率图模型的 State(St)。实验中涉及包括 40 个有代表性的 App,测试均为单台设备 1 小时,Fastbot(累积复用 3 轮测试经验)的表现均优于其他工具。下图 9 中展示了各工具在单台设备运行多次测试的对比,可以看到,Fastbot 在大型 App 上行代码覆盖率是优于其他 State of the art 工具的,侧面表明了 Fastbot 在面对大型 App 时可能更具优势。
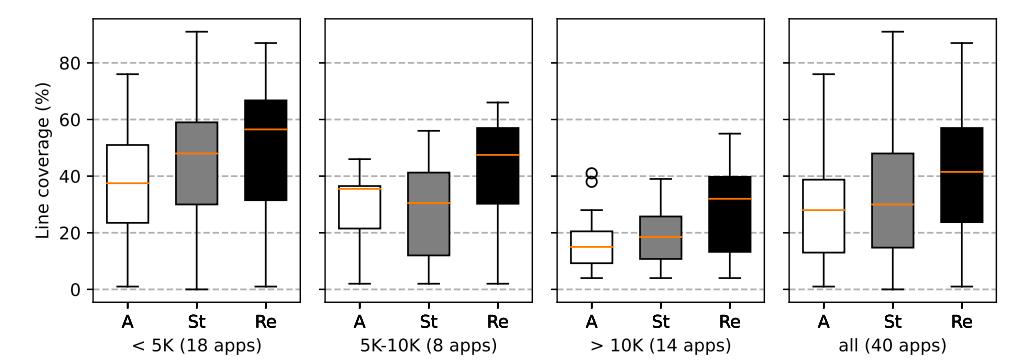
图 9 Fastbot(Re)、Ape(A)、Stoat(St) 评估数据
3.3 跨端通用性的根基
跨平台算法通用性,这一点上我们设计整体架构时已进行了充分的考虑,将客户端能力和算法决策进行了剥离解耦,通过将算法决策后端服务化来实现一套算法跨端支持。
这样解耦的好处不言而喻,对于跨平台系统端上能力来说,如 iOS,仅仅需要与 Android 端的差异性,如获取 GUI 页面信息和注入各种事件是最主要的两点不同。同时在客户端与服务端消息通信处理上,我们只需要提前约定好多个端的不同点来进行跨端兼容,如 GUI 页面信息结构化上报和下发事件类型、操作对象等通信协议的标准化上。
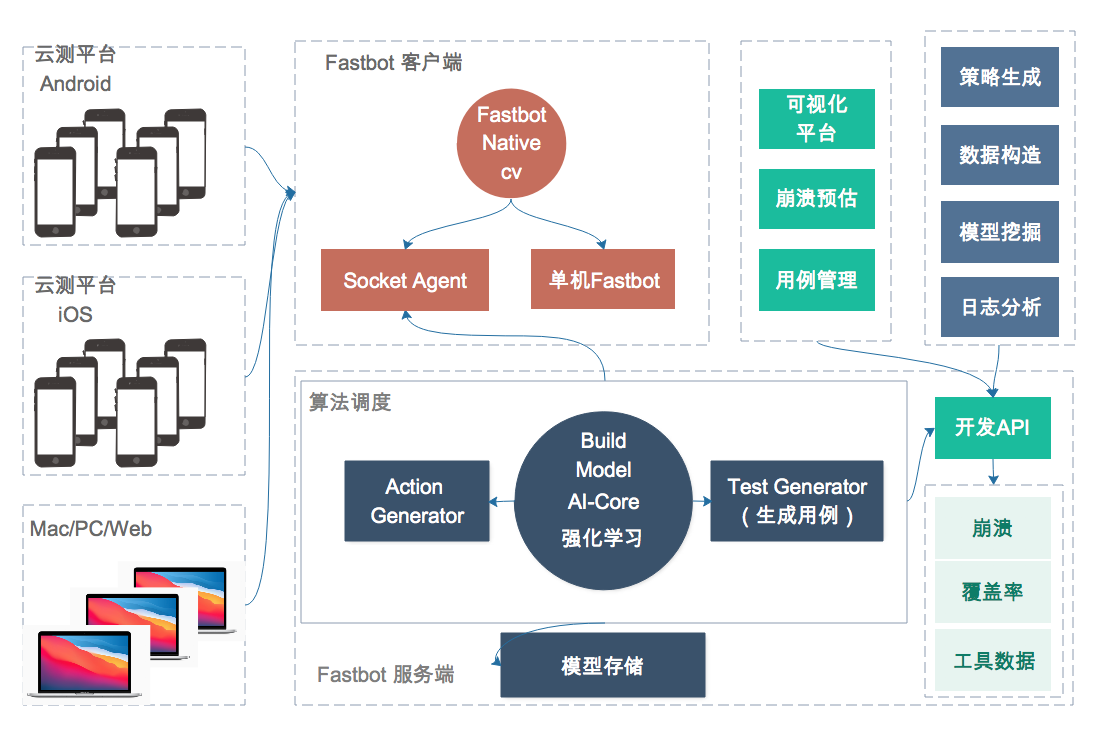
图 3 Fastbot 跨平台架构图
4. Fastbot 在跨平台中的应用
4.1 iOS 自动化测试工具和框架
由于 iOS 平台具备较强的封闭性,所以目前学术或工程上的大多数自动化测试、智能化测试的研发基本都是优先选择基于 Android 去实现的,市面上在 iOS 平台的智能测试方案还处于较为真空的状态。
在 iOS 上落地 GUI 的智能化测试的过程中, 其中一个关键点是需要对被测试 App 做一些进程操作,例如启动/杀死/重启/前后台切换等。另一个关键点是获取当前 GUI 页面信息(GUITree 控件树) ,并对其进行状态抽象, 得到 App 当前运行状态和当前页面的特征抽象表述。通常这些的基础能力会通过平台对应的自动化测试框架来实现,例如在 Android 中一般借助 Android UIAutomator(或 UIAutomator2、Accessibilityservice)抓取的 GUI 页面信息作为抽象 State 的输入。
| 公司(组织) | 关键技术 | 优点 | 缺点 | |
|---|---|---|---|---|
| UIAutomation | 苹果原生 | 基于 Accessibility 底层使用了 UI Automation 库,通过 TCP 通信的方式驱动 UI Automation 来完成自动化测试 | 官方原生兼容性有保证;无需插桩 | Xcode8.x 后废弃;只支持单台设备调试,instruments 限制单台 Mac 只能对应单台 iOS 设备 |
| XCTest/XCUITest | 苹果原生 | Xcode7.x 引入,基于 Accessibility 的 UI 测试功能框架,功能完全替代 UIAutomation,同时解除单台限制 | 官方原生兼容性有保证;较 UIAutomation 能力更强,支持正则定位 UI 元素,具备 UI assert 断言能力;支持单元测试、接口测试、UI 测试;无需插桩 | 依赖 Xcodebuild 运行;部分基础能力没有提供,如获取当前处于前台进程、高效的事件注入能力 |
| KIF | 基于 XCTest framework,引用部分私有接口 | 支持 Xcode 11.6(iOS11-13);支持单元测试、UI 测试 | 使用了私有接口,向下兼容性无法保证;运行速度偏慢 | |
| WDA(WebDriverAgent) | Facebook/Appium | 基于 XCTest framework,较 KIF 引用了更多的私有接口 | 不受 instruments 单实例的限制;开放的私有接口满足大部分测试场景;稳定性较好,后续较知名测试框架基本都有基于 WDA 扩展能力 | 使用了私有接口,向下兼容性无法保证;涉及控件查询匹配时速度较慢;Facebook 已不再维护 WDA,Appium 接手 |
| Appium | 开源社区 | 基于 WebDriver json 协议的跨平台 UI 测试框架,在 iOS 上通过 WDA 驱动对 app 的操作 | 无需插桩;支持图像识别 | 过于重量级,环境较难搭建;执行速度很慢(10 秒级) |
| Airtest | 网易 | 基于图像识别技术定位 UI 元素,同时开发了 poco 插桩库获取 GUITree 控件树 | 支持图像识别,满足在游戏场景中的自动化测试 | 新版 Xcode 适配兼容成本高 |
| EarlGrey | 基于 XCTest framework,通过 XCUITest 进行黑盒测试或通过 XCUnitTest 进行白盒测试 | 提供自动与 UI、网络请求和队列 callback,确保状态更新稳定后才执行测试 | 需要源码级插桩 | |
| tidevice | alibaba | 跨平台自动化开源工具,不依赖 Xcode 就可以启动 WebDriverAgent( WDA ) | Windows 上可运行 iOS 自动化脚本 | 同 WDA |
表 1 iOS UI 自动化框架
表 1 列举了目前市面上几款常见的 iOS UI 自动化框架。整体上可分三类,1)App 源码插桩:通过插桩 SDK 获取宿主页面控件树和进程内注入可执行操作,插桩方式执行速度快,但也有弊端,拙劣的 SDK 可能对宿主 App 有不良影响,比如稳定性变差了,此外进程内注入方式是无法操作一个系统级弹窗的。2)WDA 私有接口:这种方式的好处是无需插桩,也是目前主流的 iOS UI 自动化方案,但是往往使用了私有接口就一定带来兼容问题,其次私有接口获取控件树的性能有时也令人堪忧。3)图像识别结合 WDA 私有接口:基于此自动化能力完全取决于图像的能力,另外 2 中拥有的优缺点它也同样拥有。
表 2 是目前市面上几款相对较好的 iOS 端稳定性 Monkey 测试工具,总结来说基本都是基于 XCTest 和 WDA 来实现的,但是普遍问题是更新维护不及时,甚至是已经停止维护很久。其工具研发面临的首要问题是对 iOS 新版兼容开发成本巨大,特别是涉及 WDA(WebDriverAgent,提供了某些跨进程 App 调度和获取控件树的能力)私有接口的兼容,往往面临等待 Facebook 解决 WDA 的兼容后才能着手展开。但现实也很不幸,Facebook 目前已经放弃了对 WDA 的后续兼容,转向 IDB 研发(iOS Development Bridge,类似于安卓中的 adb 工具,但在真机上存在稳定性问题尚无法完全替代 WDA),WDA 现在则由 Appium 以社区形式接手继续迭代。
| 关键技术 | 优点 | 缺点 | |
|---|---|---|---|
| ui-auto-monkey | 最早用来做 iOS 端 Monkey 测试的工具,JavaScript 驱动,基于 UIAutomation 的 Monkey | 随着 iOS 和 Xcode 升级之后,UIAutomation 框架被砍掉了,只适用于 Xcode7.x 之前的版本,这个项目目前已弃用。 | |
| SwiftMonkey | 基于 XCUITest 框架,Swift 开发,纯坐标随机点击的 Monkey | 速度快(毫秒级),轻量级,兼容性好 | 工具需要插装到 App 源码,且不支持解析控件树 |
| FastMonkey | 基于 XCTestWD(基于 WDA 二次开发)和 SwiftMonkey 二次开发,优化 WDA 私有接口和 XCUITest,支持解析控件树,事件概率驱动的 Monkey | 速度快(毫秒级),轻量级;无需插桩,可选支持控件树解析(秒级),自定义事件配置 | 仅支持 Xcode 8.x、9.x 和 10.1 版本,其余版本尚未兼容(基于此二次开发的其他版本有兼容 xcode10.x 和 11.x) |
| OCMonkey | 基于 Objective-C 开发,集成 WDA 私有接口,可自定义配置控件类型权重驱动的 Monkey | 无需插桩,支持控件树解析 | 控件树解析速度慢(百毫秒-秒级),不支持 Xcode10.x 以上,已停止维护 |
| Macaca/iOSMonkey | 基于 Macaca 二次封装,Node.js 开发,集成 WDA 私有接口,同 Appium 类似提供外部驱动 instruments 的 server-client 自动化测试框架 | 具备跨平台支持能力,支持控件树解析 | 过于重量级,环境搭建相对复杂,事件驱动响应速度慢(10+秒级),已停止维护 |
| sjk_swiftmonkey | 基于 SwiftMonkey 二次开发的,兼容改造 WDA 私有接口,支持解析控件树,事件概率驱动的 Monkey | 轻量级,不需要插装,支持控件树解析,支持自定义事件配置,支持 Xcode 11.x | 控件树解析速度慢(秒级),不支持 Xcode12.x |
表 2 iOS Monkey 工具
除了兼容性问题,iOS 获取 GUI 页面信息能力也需要,上表 2 中多款 Monkey 工具都集成了解析 GUITree 控件树的能力,相比基于纯坐标点击,其优势在于基于控件解析的操作效率上要高很多,例如多次点击几个坐标很可能都是在同一个控件区域内反复操作;另外拥有控件解析能力后,就可以依此定制某些行为树或控件屏蔽的配置机制来丰富工具的能力;同时相对来说控件解析速度实际上也是我们需要考量的一个重要指标,作为压力测试工具我们肯定不希望 10 秒钟才点击操作一下,相反希望其拥有控件解析能力同时速度上接近基于坐标的事件产生的速度。拥有识别控件树的能力和识别所花费的耗时这两点明显是个 trade off 问题。毕竟没有哪个“疯狂的”赛车手愿意看到换个轮胎的功夫竟被第二名反超了一圈!
4.2 Fastbot-iOS 的跨平台方案
综上所述,究其利弊,Fastbot-iOS 端上架构我们采用轻量且必要的 WDA 私有接口、插桩 SDK(可选,扩展提供额外的插件能力)以及基于纯图像识别的技术方案。
具体工作流程如图 10,这里重点说明下 Fastbot-iOS 与 Android 的不同点。
首先我们在端上开发了一套基于机器视觉纯图像解析页面信息的 Fastbot Native 库,其作用是将截屏的图像转化成页面对应的结构化 GUITree XML 信息,通过 opencv 及机器视觉算法我们可以识别出 GUI 页面的布局结构、控件信息以及针对弹窗页面的结构化裁剪,该 Fastbot Native 我们是基于 c++实现的,内部设计实现上做到可多端通用,比如该库可以低成本移植到 Android 端、Mac pc 端。
其次我们出于性能和兼容性考虑对 WDA 做了优化改造,仅保留最小范围的 WDA 私有接口,这样设计带来的好处是提供工具高可用性以及可快速兼容最新版的 iOS,甚至不需要做任何改造,例如苹果推出 iOS15 当天 Fastbot-iOS 就无缝兼容可以直接跑起来了。
最后我们又提供了插件可扩展能力,如 App 内集成 ShootsSDK 插件(Shoots 是字节跳动内部研发的一款通用 UI 自动化框架,用于编写 UI 自动化测试用例,类似市面上 Airtest 的 poco SDK),该插件通过 App 内部反射方式获取 App 的 GUITree 控件树,通常仅在 Webview、Lynx、游戏及业务有特殊页面解析需求时才引入,更一般情况下通过 Fastbot Native 库就可解决页面解析问题。同时该扩展机制支持业务内自研发定制插件,只需要对齐我们 Fastbot-iOS 的通信协议即可。
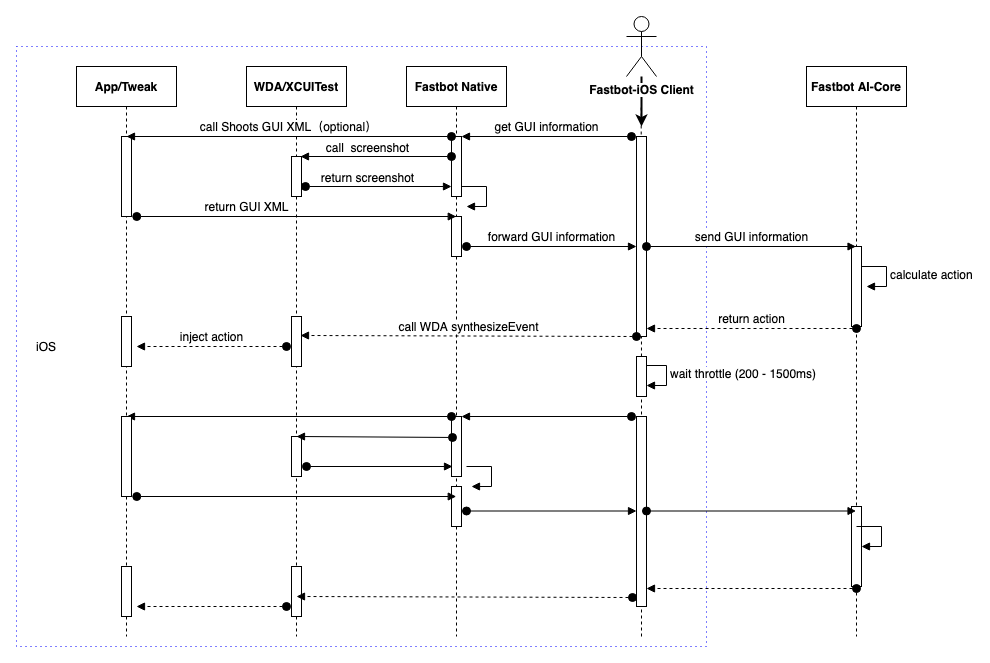
图 10 Fastbot-iOS 动作时序图
4.2.1 可测性提升
除了 Shoots 插件外,Fastbot-iOS 还研发了 AAFastbotTweak 可测性插件,如其名,该插件同样集成在 App 内,为 App 提供测试增强可扩展能力,能力包括但不限于:
场景限定:能够将宿主 App 限定到一个场景下,可以进入到该场景的任意子页面,如果退出该场景 Fastbot-iOS 会立即重新进入限定的场景页面。同时提供了黑白名单机制,限定哪些页面不能跳转或者只能跳转到哪些页面。 屏蔽跳转:周期性屏蔽 QQ,,淘宝等其他所有第三方外跳。 屏蔽升级:屏蔽宿主 App 自动更新。 自动登录:从账号池中获取指定类型账号并自动完成登录。 数据 Mock:Mock 预置的 A/B Testing 的 value 和 keys。 强制性 kill:接收到执行的消息后,强杀 App,例如 WatchDog 强杀。 Schema 跳转:根据预置的 Schema List 读取并自动跳转到指定的场景页面。
以上这些功能均是可插拔、可按需启动、可高度定制化的。
4.2.2 故障注入
除了上述两种 SDK 外,Fastbot-iOS 还研发了故障注入 SDK,也集成于 App 内,该插件为模拟线上设备各种复杂极端情况,在运行 Fastbot 遍历测试同时打入瞬时或持续性故障来验证极端情况下的 App 稳定性,其能力包括不限于:
模拟 CPU 高负载:采用高频的计算增加 CPU 的负载,模拟使多数线程处于跑满状态,单线程处于波动状态。 模拟 CPU 降频:对越狱 iPhone 低电量模式下的"最大 CPU 频率"数值进行调节,模拟设备低频高温状态。 模拟低可用内存:采用一次性分配不可释放的内存抢占内存,使 App 处于低可用内存状态下运行测试。 模拟磁盘异常:采用随机数生成超大文件然后 copy,对 copy 文件随机插入字符,创造低可用磁盘或无可用磁盘情况。 模拟高 IO:长时间处于写入和擦除状态,使用少量磁盘和内存进行 I/O 模拟。 模拟线程或线程池高并发:线程执行前增加计数锁,制造对临界资源的高并发访问。
以上功能业务可按需接入,同时支持多种故障混合。
4.2.3 WDA 优化
对 WDA 的改造是出于性能和兼容性的考虑,心无旁骛,不断尝试直至满足最小化使用原则,最终我们仅保留了如下三个接口,其他部分的私有接口全都替换为 XCUITest 原生接口:
前台进程句柄相关私有接口:(NSArray _)activeApplications; Application 初始化相关私有接口:(id)initPrivateWithPath:(id)arg1 bundleID:(id)arg2; 生成设备事件私有接口:(void)synthesizeEvent:(XCSynthesizedEventRecord _)arg1 completion:(void (^)(NSError _))arg2。
这样解耦后的 Fastbot-iOS 更轻量化,对之后 iOS 兼容迭代我们只需要在这些私有接口上。
此外前面表 2 中列出来的 iOS-Monkey 工具,如 OCMonkey 一般都是调用自动化框架 XCUITest 或 WDA 来解析 GUI 页面信息,这种方式存在一个值得的稳定性问题,首先 Fastbot-iOS 是以第三方进程的角色去解析被测试 App 的,通过 XCUITest 或 WDA dump GUITree 时会涉及递归解析页面元素,在复杂页面下这样的递归会引起资源占用问题,会出现比较高概率引起中断连接或者超时情况, 更甚的是在低配的 iPhone 手机上运行 10 小时以上就会产生比较明显的电池过热,长时间如此则有电池鼓包的风险。因此我们选择在业务没有引入 Shoots 插件情况时(默认情况我们希望工具完全基于非插桩无需接入这类插件,因为接入插件意味 App 有一定改造成本,而且也不适用于 release 包测试,特殊情况或想提升扩展能力才接入,接入与否也属于 trade off 问题)完全放弃常规的解析页面的方式,转而使用跨平台的图像结构化编码技术,具体应用时,只需要依赖一个 XCUITest 的截屏接口即可, 并且此能力可以直接对系统层面的所有内容截屏,天生支持应用内和应用外页面的解析。
5. Fastbot 智能图像处理拓展跨平台能力
5.1 图像算法在测试领域的应用
智能图像处理是指一类基于计算机的自适应与各种应用场合的图像处理和分析技术,本身是一个独立的理论和技术领域,但同时又是机器视觉中十分重要的一项技术。
机器视觉的起源可追溯到 20 世纪 60 年代美国学者 L.R.罗伯兹对多面体积木世界的图像处理研究,70 年代麻省理工学院(MIT)人工智能实验室“机器视觉”课程的开设。到 80 年代,全球性机器视觉研究热潮开始兴起,出现了一些基于机器视觉的应用系统。90 年代以后,随着计算机和半导体技术的飞速发展,机器视觉的理论和应用得到进一步发展。
进入 21 世纪后,机器视觉技术的发展速度更快,已经大规模地应用于多个领域,如智能制造、智能交通、医疗卫生、安防监控等领域。目前,随着人工智能浪潮的兴起,机器视觉技术正处于不断突破、走向成熟的新阶段。
据调研测试领域中目前已有越来越多的公司、学术组织将图像处理、机器视觉引入其中,使用场景也逐渐丰富,同时也产生了大量优秀工具。表 3 中列举了几款有代表的图像能力的测试工具。看到其中不乏亮点的感觉就是“如同茫茫暗夜中行船发现了一盏指路明灯一般”。
| 时间 | 公司(组织) | 图像技术 | 应用领域 | |
|---|---|---|---|---|
| Sikuli | 2009 开源 | MIT | 基于屏幕图像控件的识别,技术上采用 OpenCV 中的模板匹配和 SIFT 特征值匹配 | 1、UI 自动化;2、图像匹配 |
| Applitools | 2017.07 | Applitools | 采用自适应算法来进行可视化测试,通过 diff 发现 UI 潜在错误,原理是人工在 baseline 的每步图里打 checkpoint,利用图像算法对 checkpoint 的对比来断言 | 1、功能测试;2、回归测试 |
| AirTest | 2018.03 发布 | 网易 | 基于图像识别的自动化测试框架,原理源于 Sikuli | 1、游戏 UI 识别;2、跨平台 AppUI 识别 |
| Test.ai | 2018.08 | Test.ai | 在应用程序中动态识别屏幕和元素,并自动驱动应用程序执行测试用例 | 1、UI 遍历测试;2、对象检测 |
| Appium1.9 | 2018.08 | Appium | 加入基于图像控件的识别定位能力 | 1、UI 自动化 |
| AppiumPro | 2018.11 | Cloud Grey | 将 Test.ai 作为插件,使用深度对象检测实现控件识别 | 1、对象检测 |
表 3 图像算法在测试领域的应用
5.2 图像 UI 识别
在 Fastbot 低能耗、低耗时、高性能前提要求下,我们优先选用最基础的图像处理技术来识别 GUI 界面信息,可以在毫秒级完成构建一个页面的信息。基础图像处理包括:
基础分割:
预处理:包括裁剪、灰度直方图均衡、二值化。裁剪主要针对页面侧面的上下拖动条,在行扫描的时候会导致 badcase,处理时会先把右侧一列裁减掉。灰度直方图均衡主要针对一些整图较暗的情况,通常是夜间模式,均衡后背景和 UI 的对比度会变高。二值化将小于特定阈值的像素点置 0,大于阈值的置 1。 行列扫描:对二值图由上到下或由左到右扫描一行像素值,若全为 1(浅色),视为非 UI 区域,若不全为 1,视为 UI 区域。交替行列扫描迭代多次,基本可分割一张图片,如下图 11。
图 11 行列扫描
文字块聚合:对相邻 UI 类型为 text 的 UI 合并成一个整体。先进行文字行聚合,然后进行列聚合。如下图 12
图 12 文字块聚合
夜间模式:若分割出区域数量过少,则判定出现夜间模式,会先进行灰度直方图均衡,再调整二值化阈值进行分割。如图 13

图 13 夜间模式
同时在对性能要求较为宽容的时,我们引入深度机器学习相关技术提高页面解析的精准度:
分类:将检测到的控件进行分类,区分按钮/搜索框/图片/文本/短文本等。 OCR:文字识别,可用于检索自定义事件。 目标检测:利用 YOLOv3 目标检测模型直接定位预先标注的控件。

图 14 目标检测
5.3 图像 UI 异常检测
除了 UI 界面信息的识别外,我们也研发了较丰富的图像 UI 异常检测能力。能力包括不限于:
黑白屏:黑屏、白屏异常,一般由于图像路径错误、应用权限、网络断线等原因,造成图像加载错误,从而导致界面上图像完全无法渲染。 图像重叠:多个图像间相互重叠,通常这种情况是由于图像异步渲染加载出现性能卡顿造成。 紫块异常:紫色块异常通常出现在游戏场景中,常造成紫色块异常的原因是贴图或者模型图片的损坏或者丢失。 白块异常:白色块异常通常出现在游戏场景中,造成白色块异常的原因是 UI 图片的损坏或者丢失。 黑框异常:图片四周有超过阈值宽度的黑色区域,通常是机型、布局兼容性适配不足造成。 过爆异常:通常出现在游戏场景中,通常由于游戏引擎渲染出现错误造成。 控件遮挡:下图 15 左 1,一个控件堆叠到了另一个控件的上层,从而完全挡住了下层控件,这种情况常常是由于控件的长宽比或者控件文字大小设置出错。 文字重叠:下图 15 左 2,两个文本框内的文字发生了重叠,这通常是由于文字大小设定出错,文字重叠不同于控件遮挡,是两部分文字混淆在一起了,而控件遮挡是一个控件完全挡住了另一个控件。 图像丢失:下图 15 左 3,由于图像路径设成错误、应用权限、网络断线等原因,造成图像加载错误,从而导致界面上图像显示不完全。 空值:下图 15 左 4,由于参数设置错误或数据库读取出错导致界面上文字的显示出错。 花屏:下图 15 右 1,游戏或视频中的花屏异常,通常原因是由于硬件缺陷或者使用 GPU/CPU 加速指令时出现了错误。
图 15 UI 异常检测示例
6. Fastbot 在游戏测试中的应用
近年来强化学习已经能够学会玩围棋,星际,Dota 等游戏,甚至能够超越人类职业玩家,这些技术突破不仅带来了游戏 AI 设计的革新,也为智能化的游戏测试提供了可能。针对游戏业务提出的真实需求,Fastbot 在结合当前人工智能技术在游戏测试方向进行了很多的探索和尝试。
多语言检测:针对朝夕光年多款游戏相继出海,游戏国际化多语言测试人力不足背景下,我们通过 Fastbot 实现游戏 UI 遍历,同时截取游戏屏幕,通过 OCR 文本识别,比对文本信息与文本区域识别翻译缺失、翻译错误、文本超框等问题。

图 16 RO 仙境传说游戏-语种翻译错误-泰语中出现英语
自动过任务 AI:针对游戏过程中需先完成某些剧情任务才能到的场景,我们自研了一套 Fastbot-a3c Agent 算法,通过结合游戏状态图,行为树规则先验知识以及模仿学习实现了游戏自动做任务来满足游戏长时间稳定性、兼容性测试及国际化多语言检测。

动画 3 RO 仙境传说游戏自动做任务 AI
7. 总结
目前,Fastbot 已广泛应用于字节客户端类产品的稳定性测试与兼容性测试。每日启动任务数超过 1 万次,每月平均发现 5 万个以上的崩溃。借助 Fastbot 的能力,我们在发版前就可以修复大部分的 crash,确保线上用户的使用体验。同时,Fastbot 在整个 DevOps 流程扮演重要的基础服务角色。
同时,我们开源了:
Fastbot-iOS: https://github.com/bytedance/Fastbot_iOS Fastbot-Android: https://github.com/bytedance/Fastbot_Android
希望与业内同行深入合作交流,我们相信,越来越多的智能化测试工具落地,将会加速质量工程领域的变革,推动国内质量工程技术水平走到全球质量工程工业界前沿。
本文结尾,我们由衷感谢产研质量工程、产研 iOS 客户端平台架构、Data 视觉技术、产研游戏 AI 和游戏质量效能的各组同学鼎力支持。
Fastbot QQ 交流群:1164712203 Fastbot 交流群:

8. 加入我们
字节跳动 Quality Lab,是致力于面向互联网行业的软件工程理论研究与技术预研的创新团队,我们的使命是成为全球顶尖的智能工具团队。我们致力于将前沿的 AI 技术应用到质量与工程效能领域,面向行业提供智能化测试工具,例如 Fastbot、ByQI、SmartEye、SmartUnit 等测试服务。在成为全球顶尖的智能工具团队道路上,希冀为质量领域带来更多智能化手段。
在这里,你可以用机器视觉与强学,创造具有超强能力的测试机器人,并在数以千计的设备上验证你的算法;还可以实践各种教科书上的测试理论,去帮助业务提升测试效率,组合测试、程序分析,还有精准测试,自动生成单测,缺陷自动修复,都等着你来探索;更可以与国内外顶尖机构进行交流合作,与世界各地的学者一起探索更多软件工程领域的可能性。欢迎各位有识之士加入我们。简历投递邮箱:qualitylab@bytedance.com;邮件标题:姓名 - 工作年限 - Quality Lab - Fastbot。
9. 相关资料
Sapienz:Intelligent automated software testing at scale,https://engineering.fb.com/2018/05/02/developer-tools/sapienz-intelligent-automated-software-testing-at-scale/ Dynodroid:an input generation system for Android apps,https://dl.acm.org/doi/10.1145/2491411.2491450 EHBDroid:Beyond GUI testing for Android applications,https://ieeexplore.ieee.org/document/8115615 Stoat:Guided, Stochastic Model-Based GUI Testing of Android Apps,https://tingsu.github.io/files/stoat.html APE:Practical GUI Testing of Android Applications via Model Abstraction and Refinement,https://helloqirun.github.io/papers/icse19_tianxiao.pdf TimeMachine:Time-travel Testing of Android Apps,https://www.comp.nus.edu.sg/~dongz/res/time-travel-testing-21-01-2020.pdf Q-Testing:Reinforcement Learning Based Curiosity-Driven Testing of Android Applications,https://minxuepan.github.io/Pubs/Q-testing.pdf ComboDroid:generating high-quality test inputs for Android apps via use case combinations,https://dl.acm.org/doi/10.1145/3377811.3380382 Google Monkey,https://developer.android.com/studio/test/monkey Droidbot:a lightweight UI-Guided test input generator for android,https://ieeexplore.ieee.org/document/7965248 Humanoid:A Deep Learning-Based Approach to Automated Black-box Android App Testing,https://ieeexplore.ieee.org/document/8952324 Wuji:Automatic Online Combat Game Testing Using Evolutionary Deep Reinforcement Learning,https://yanzzzzz.github.io/files/PID6139619.pdf The Game Imitation: Deep Supervised Convolutional Networks for Quick Video Game AI,https://arxiv.org/abs/1702.05663 Automated Video Game Testing Using Synthetic and Human-Like Agents,https://ieeexplore.ieee.org/document/8869824 Counter-Strike Deathmatch with Large-Scale Behavioural Cloning,https://arxiv.org/pdf/2104.04258.pdf Developed based on the following tools: zalando/SwiftMonkey b1ueshad0w/OCMonkey zhangzhao4444/Fastmonkey facebook/WebDriverAgent AirtestProject/Airtest tianxiaogu/ape zhangzhao4444/Maxim tingsu/Stoat skull591/ComboDroid-Artifact yzygitzh/Humanoid anlalalu/Q-testing
点个在看杀个 Bug ❤










![小马哥IOS第11期ReactNative跨平台开发视频教程 [复制链接]](https://static.kouhao8.com/sucaidashi/xkbb/6328f20ad68bb340175842b0f6726415.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)





![[人工智能] 美国尖端人工智能视频教程 人工智能AI课程视频教程 785集 英文带字幕](https://static.kouhao8.com/sucaidashi/xkbb/c7c0156cc2340f0672931bac99481273.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)



![[Python] Python跨域电商实战+Python前后端分离开发课程Vue-Django REST fr](https://static.kouhao8.com/sucaidashi/xkbb/490160590fa102677140a8524e4e0415.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)

相关资源