

HashMap 面试常见的6连问,你能扛得住吗?
发布于 2021-11-24 15:10 ,所属分类:2021面试经验技巧分享
点击gongzhong号,利用碎片时间学习
高手过招,招招致命
JDK1.8 中 HashMap 的底层实现,我相信大家都能说上来个 一二,底层数据结构 数组 + 链表(或红黑树) ,源码如下
/**
*数组
*/
transientNode<K,V>[]table;
/**
*链表结构
*/
staticclassNode<K,V>implementsMap.Entry<K,V>{
finalinthash;
finalKkey;
Vvalue;
Node<K,V>next;
Node(inthash,Kkey,Vvalue,Node<K,V>next){
this.hash=hash;
this.key=key;
this.value=value;
this.next=next;
}
publicfinalKgetKey(){returnkey;}
publicfinalVgetValue(){returnvalue;}
publicfinalStringtoString(){returnkey+"="+value;}
publicfinalinthashCode(){
returnObjects.hashCode(key)^Objects.hashCode(value);
}
publicfinalVsetValue(VnewValue){
VoldValue=value;
value=newValue;
returnoldValue;
}
publicfinalbooleanequals(Objecto){
if(o==this)
returntrue;
if(oinstanceofMap.Entry){
Map.Entry<?,?>e=(Map.Entry<?,?>)o;
if(Objects.equals(key,e.getKey())&&
Objects.equals(value,e.getValue()))
returntrue;
}
returnfalse;
}
}
/**
*红黑树结构
*/
staticfinalclassTreeNode<K,V>extendsLinkedHashMap.Entry<K,V>{
TreeNode<K,V>parent;//red-blacktreelinks
TreeNode<K,V>left;
TreeNode<K,V>right;
TreeNode<K,V>prev;//neededtounlinknextupondeletion
booleanred;
...
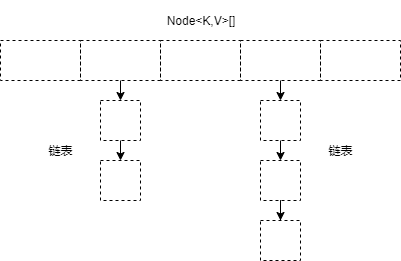
但面试往往会问的比较细,例如下面的容量问题,我们能答上来几个?
1、table 的初始化时机是什么时候,初始化的 table.length 是多少、阀值(threshold)是多少,实际能容下多少元素
2、什么时候触发扩容,扩容之后的 table.length、阀值各是多少?
3、table 的 length 为什么是 2 的 n 次幂
4、求索引的时候为什么是:h&(length-1),而不是 h&length,更不是 h%length
5、 Map map = new HashMap(1000); 当我们存入多少个元素时会触发map的扩容;Map map1 = new HashMap(10000); 我们存入第 10001个元素时会触发 map1 扩容吗
6、为什么加载因子的默认值是 0.75,并且不推荐我们修改
由于我们平时的少,一旦碰上这样的 连击 + 暴击,我们往往不知所措、无从应对;接下来我们看看上面的 6 个问题,是不是真的难到无法理解 ,还是我们不够细心、在自信的自我认为
斗智斗勇,见招拆招
上述的问题,我们如何去找答案 ? 方式有很多种,用的最多的,我想应该是上网查资料、看别人的博客,但我认为最有效、准确的方式是读源码
问题 1:table 的初始化
HashMap 的构造方法有如下 4 种
/**
*构造方法1
*
*通过指定的initialCapacity和loadFactor实例化一个空的HashMap对象
*/
publicHashMap(intinitialCapacity,floatloadFactor){
if(initialCapacity<0)
thrownewIllegalArgumentException("Illegalinitialcapacity:"+
initialCapacity);
if(initialCapacity>MAXIMUM_CAPACITY)
initialCapacity=MAXIMUM_CAPACITY;
if(loadFactor<=0||Float.isNaN(loadFactor))
thrownewIllegalArgumentException("Illegalloadfactor:"+
loadFactor);
this.loadFactor=loadFactor;
this.threshold=tableSizeFor(initialCapacity);
}
/**
*构造方法2
*
*通过指定的initialCapacity和默认的loadFactor(0.75)实例化一个空的HashMap对象
*/
publicHashMap(intinitialCapacity){
this(initialCapacity,DEFAULT_LOAD_FACTOR);
}
/**
*构造方法3
*
*通过默认的initialCapacity和默认的loadFactor(0.75)实例化一个空的HashMap对象
*/
publicHashMap(){
this.loadFactor=DEFAULT_LOAD_FACTOR;//allotherfieldsdefaulted
}
/**
*
*构造方法4
*通过指定的Map对象实例化一个HashMap对象
*/
publicHashMap(Map<?extendsK,?extendsV>m){
this.loadFactor=DEFAULT_LOAD_FACTOR;
putMapEntries(m,false);
}
构造方式 4 和 构造方式 1 实际应用的不多,构造方式 2 直接调用的 1(底层实现完全一致),构造方式 2 和 构造方式 3 比较常用,而最常用的是构造方式 3;此时我们以构造方式 3 为前提来分析,而构造方式 2 我们则在问题 5 中来分析
使用方式 1 实例化 HashMap 的时候,table 并未进行初始化,那 table 是何时进行初始化的了 ?平时我们是如何使用 HashMap 的,先实例化、然后 put、然后进行其他操作,如下
Map<String,Object>map=newHashMap();
map.put("name","张三");
map.put("age",21);
//后续操作
...
既然实例化的时候未进行 table 的初始化,那是不是在 put 的时候初始化的了,我们来确认下
resize() 初始化 table 或 对 table 进行双倍扩容,源码如下(注意看注释)
/**
*Initializesordoublestablesize.Ifnull,allocatesin
*accordwithinitialcapacitytargetheldinfieldthreshold.
*Otherwise,becauseweareusingpower-of-twoexpansion,the
*elementsfromeachbinmusteitherstayatsameindex,ormove
*withapoweroftwooffsetinthenewtable.
*
*@returnthetable
*/
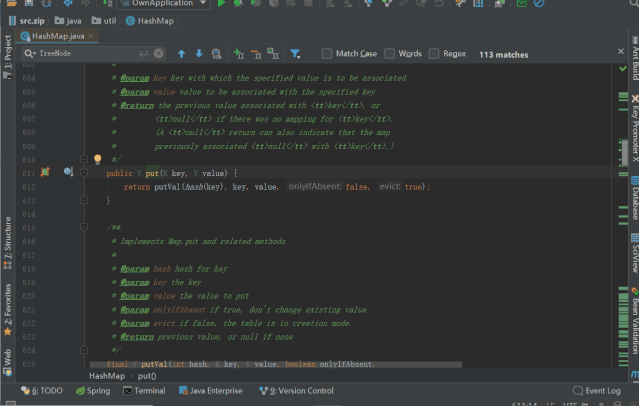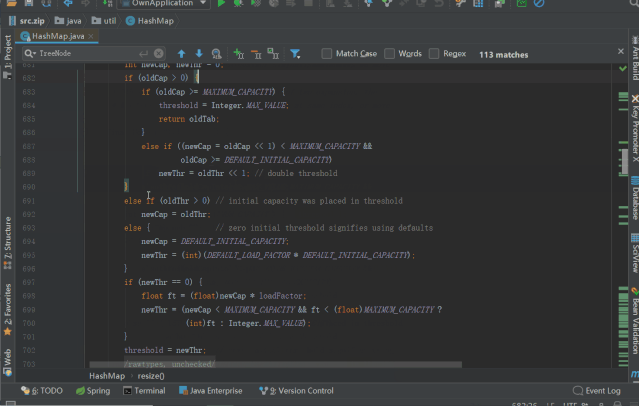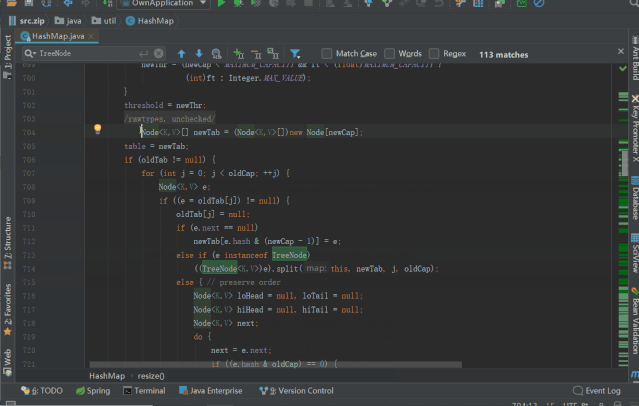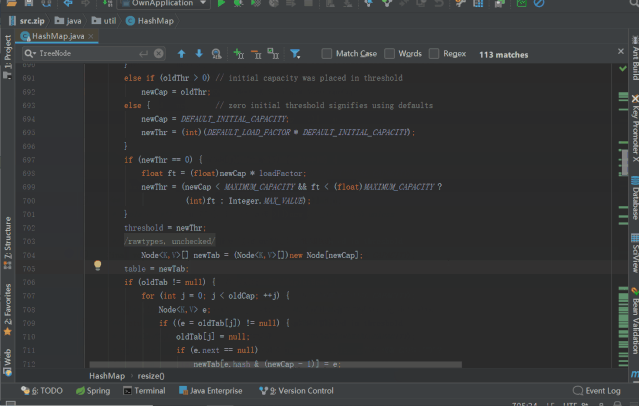
finalNode<K,V>[]resize(){
Node<K,V>[]oldTab=table;//第一次put的时候,table=null
intoldCap=(oldTab==null)?0:oldTab.length;//oldCap=0
intoldThr=threshold;//threshold=0,oldThr=0
intnewCap,newThr=0;
if(oldCap>0){//条件不满足,往下走
if(oldCap>=MAXIMUM_CAPACITY){
threshold=Integer.MAX_VALUE;
returnoldTab;
}
elseif((newCap=oldCap<<1)<MAXIMUM_CAPACITY&&
oldCap>=DEFAULT_INITIAL_CAPACITY)
newThr=oldThr<<1;//doublethreshold
}
elseif(oldThr>0)//initialcapacitywasplacedinthreshold
newCap=oldThr;
else{//zeroinitialthresholdsignifiesusingdefaults走到这里,进行默认初始化
newCap=DEFAULT_INITIAL_CAPACITY;//DEFAULT_INITIAL_CAPACITY=1<<4=16,newCap=16;
newThr=(int)(DEFAULT_LOAD_FACTOR*DEFAULT_INITIAL_CAPACITY);//newThr=0.75*16=12;
}
if(newThr==0){//条件不满足
floatft=(float)newCap*loadFactor;
newThr=(newCap<MAXIMUM_CAPACITY&&ft<(float)MAXIMUM_CAPACITY?
(int)ft:Integer.MAX_VALUE);
}
threshold=newThr;//threshold=12;重置阀值为12
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[]newTab=(Node<K,V>[])newNode[newCap];//初始化newTab,length=16;
table=newTab;//table初始化完成,length=16;
if(oldTab!=null){//此时条件不满足,后续扩容的时候,走此if分支将数组元素复制到新数组
for(intj=0;j<oldCap;++j){
Node<K,V>e;
if((e=oldTab[j])!=null){
oldTab[j]=null;
if(e.next==null)
newTab[e.hash&(newCap-1)]=e;
elseif(einstanceofTreeNode)
((TreeNode<K,V>)e).split(this,newTab,j,oldCap);
else{//preserveorder
Node<K,V>loHead=null,loTail=null;
Node<K,V>hiHead=null,hiTail=null;
Node<K,V>next;
do{
next=e.next;
if((e.hash&oldCap)==0){
if(loTail==null)
loHead=e;
else
loTail.next=e;
loTail=e;
}
else{
if(hiTail==null)
hiHead=e;
else
hiTail.next=e;
hiTail=e;
}
}while((e=next)!=null);
if(loTail!=null){
loTail.next=null;
newTab[j]=loHead;
}
if(hiTail!=null){
hiTail.next=null;
newTab[j+oldCap]=hiHead;
}
}
}
}
}
returnnewTab;//新数组
}
自此,问题 1 的答案就明了了
table 的初始化时机是什么时候
一般情况下,在第一次 put 的时候,调用 resize 方法进行 table 的初始化(懒初始化,懒加载思想在很多框架中都有应用!)
初始化的 table.length 是多少、阀值(threshold)是多少,实际能容下多少元素
默认情况下,table.length = 16; 指定了 initialCapacity 的情况放到问题 5 中分析
默认情况下,threshold = 12; 指定了 initialCapacity 的情况放到问题 5 中分析
默认情况下,能存放 12 个元素,当存放第 13 个元素后进行扩容
问题 2 :table 的扩容
putVal 源码如下
/**
*ImplementsMap.putandrelatedmethods
*
*@paramhashhashforkey
*@paramkeythekey
*@paramvaluethevaluetoput
*@paramonlyIfAbsentiftrue,don'tchangeexistingvalue
*@paramevictiffalse,thetableisincreationmode.
*@returnpreviousvalue,ornullifnone
*/
finalVputVal(inthash,Kkey,Vvalue,booleanonlyIfAbsent,
booleanevict){
Node<K,V>[]tab;Node<K,V>p;intn,i;
if((tab=table)==null||(n=tab.length)==0)
n=(tab=resize()).length;
if((p=tab[i=(n-1)&hash])==null)
tab[i]=newNode(hash,key,value,null);
else{
Node<K,V>e;Kk;
if(p.hash==hash&&
((k=p.key)==key||(key!=null&&key.equals(k))))
e=p;
elseif(pinstanceofTreeNode)
e=((TreeNode<K,V>)p).putTreeVal(this,tab,hash,key,value);
else{
for(intbinCount=0;;++binCount){
if((e=p.next)==null){
p.next=newNode(hash,key,value,null);
if(binCount>=TREEIFY_THRESHOLD-1)//-1for1st
treeifyBin(tab,hash);
break;
}
if(e.hash==hash&&
((k=e.key)==key||(key!=null&&key.equals(k))))
break;
p=e;
}
}
if(e!=null){//existingmappingforkey
VoldValue=e.value;
if(!onlyIfAbsent||oldValue==null)
e.value=value;
afterNodeAccess(e);
returnoldValue;
}
}
++modCount;
if(++size>threshold)//当size(已存放元素个数)>thrshold(阀值),进行扩容
resize();
afterNodeInsertion(evict);
returnnull;
}
还是调用 resize() 进行扩容,但与初始化时不同(注意看注释)
/**
*Initializesordoublestablesize.Ifnull,allocatesin
*accordwithinitialcapacitytargetheldinfieldthreshold.
*Otherwise,becauseweareusingpower-of-twoexpansion,the
*elementsfromeachbinmusteitherstayatsameindex,ormove
*withapoweroftwooffsetinthenewtable.
*
*@returnthetable
*/
finalNode<K,V>[]resize(){
Node<K,V>[]oldTab=table;//此时的table!=null,oldTab指向旧的table
intoldCap=(oldTab==null)?0:oldTab.length;//oldCap=table.length;第一次扩容时是16
intoldThr=threshold;//threshold=12,oldThr=12;
intnewCap,newThr=0;
if(oldCap>0){//条件满足,走此分支
if(oldCap>=MAXIMUM_CAPACITY){
threshold=Integer.MAX_VALUE;
returnoldTab;
}
elseif((newCap=oldCap<<1)<MAXIMUM_CAPACITY&&//oldCap左移一位;newCap=16<<1=32;
oldCap>=DEFAULT_INITIAL_CAPACITY)
newThr=oldThr<<1;//doublethreshold//newThr=12<<1=24;
}
elseif(oldThr>0)//initialcapacitywasplacedinthreshold
newCap=oldThr;
else{//zeroinitialthresholdsignifiesusingdefaults
newCap=DEFAULT_INITIAL_CAPACITY;//DEFAULT_INITIAL_CAPACITY=1<<4=16,newCap=16;
newThr=(int)(DEFAULT_LOAD_FACTOR*DEFAULT_INITIAL_CAPACITY);
}
if(newThr==0){//条件不满足
floatft=(float)newCap*loadFactor;
newThr=(newCap<MAXIMUM_CAPACITY&&ft<(float)MAXIMUM_CAPACITY?
(int)ft:Integer.MAX_VALUE);
}
threshold=newThr;//threshold=newThr=24;重置阀值为24
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[]newTab=(Node<K,V>[])newNode[newCap];//初始化newTab,length=32;
table=newTab;//table指向newTab,length=32;
if(oldTab!=null){//扩容后,将oldTab(旧table)中的元素移到newTab(新table)中
for(intj=0;j<oldCap;++j){
Node<K,V>e;
if((e=oldTab[j])!=null){
oldTab[j]=null;
if(e.next==null)
newTab[e.hash&(newCap-1)]=e;//
elseif(einstanceofTreeNode)
((TreeNode<K,V>)e).split(this,newTab,j,oldCap);
else{//preserveorder
Node<K,V>loHead=null,loTail=null;
Node<K,V>hiHead=null,hiTail=null;
Node<K,V>next;
do{
next=e.next;
if((e.hash&oldCap)==0){
if(loTail==null)
loHead=e;
else
loTail.next=e;
loTail=e;
}
else{
if(hiTail==null)
hiHead=e;
else
hiTail.next=e;
hiTail=e;
}
}while((e=next)!=null);
if(loTail!=null){
loTail.next=null;
newTab[j]=loHead;
}
if(hiTail!=null){
hiTail.next=null;
newTab[j+oldCap]=hiHead;
}
}
}
}
}
returnnewTab;
}
自此,问题 2 的答案也就清晰了
什么时候触发扩容,扩容之后的 table.length、阀值各是多少
当 size > threshold 的时候进行扩容
扩容之后的 table.length = 旧 table.length * 2,
扩容之后的 threshold = 旧 threshold * 2
问题 3、4 :2 的 n 次幂
table 是一个数组,那么如何最快的将元素 e 放入数组 ?当然是找到元素 e 在 table 中对应的位置 index ,然后 table[index] = e; 就好了;如何找到 e 在 table 中的位置了 ?
我们知道只能通过数组下标(索引)操作数组,而数组的下标类型又是 int ,如果 e 是 int 类型,那好说,就直接用 e 来做数组下标(若 e > table.length,则可以 e % table.length 来获取下标),可 key - value 中的 key 类型不一定,所以我们需要一种统一的方式将 key 转换成 int ,最好是一个 key 对应一个唯一的 int (目前还不可能, int有范围限制,对转换方法要求也极高),所以引入了 hash 方法
staticfinalinthash(Objectkey){
inth;
return(key==null)?0:(h=key.hashCode())^(h>>>16);//这里的处理,有兴趣的可以琢磨下;能够减少碰撞
}
实现 key 到 int 的转换(关于 hash,本文不展开讨论)。拿到了 key 对应的 int h 之后,我们最容易想到的对 value 的 put 和 get 操作也许如下
//put
table[h%table.length]=value;
//get
e=table[h%table.length];
直接取模是我们最容易想到的获取下标的方法,但是最高效的方法吗 ?
我们知道计算机中的四则运算最终都会转换成二进制的位运算
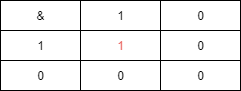
我们可以发现,只有 & 数是1时,& 运算的结果与被 & 数一致
1&1=1;
0&1=0;
1&0=0;
0&0=0;
这同样适用于多位操作数
1010&1111=1010;=>10&15=10;
1011&1111=1011;=>11&15=11;
01010&10000=00000;=>10&16=0;
01011&10000=00000;=>11&16=0;
我们是不是又有所发现:10 & 16 与 11 & 16 得到的结果一样,也就是冲突(碰撞)了,那么 10 和 11 对应的 value 会在同一个链表中,而 table 的有些位置则永远不会有元素,这就导致 table 的空间未得到充分利用,同时还降低了 put 和 get 的效率(对比数组和链表);由于是 2 个数进行 & 运算,所以结果由这两个数决定,如果我们把这两个数都做下限制,那得到的结果是不是可控制在我们想要的范围内了 ?
我们需要利用好 & 运算的特点,当右边的数的低位二进制是连续的 1 ,且左边是一个均匀的数(需要 hash 方法实现,尽量保证 key 的 h 唯一),那么得到的结果就比较完美了。低位二进制连续的 1,我们很容易想到 2^n - 1; 而关于左边均匀的数,则通过 hash 方法来实现,这里不做细究了。更多面试题,欢迎 gongzhong号Java面试题精选
自此,2 的 n 次幂的相关问题就清楚了
table 的 length 为什么是 2 的 n 次幂
为了利用位运算 & 求 key 的下标
求索引的时候为什么是:h&(length-1),而不是 h&length,更不是 h%length
h%length 效率不如位运算快
h&length 会提高碰撞几率,导致 table 的空间得不到更充分的利用、降低 table 的操作效率
给各位留个疑问:为什么不直接用 2^n-1 作为 table.length ?欢迎评论区留言
问题 5:指定 initialCapacity
当我们指定了 initialCapacity,HashMap的构造方法有些许不同,如下所示
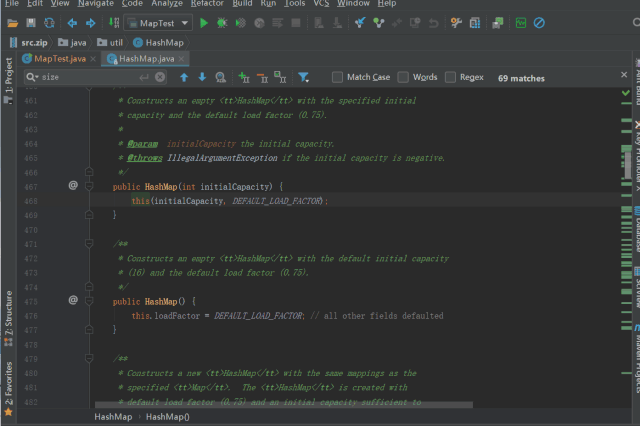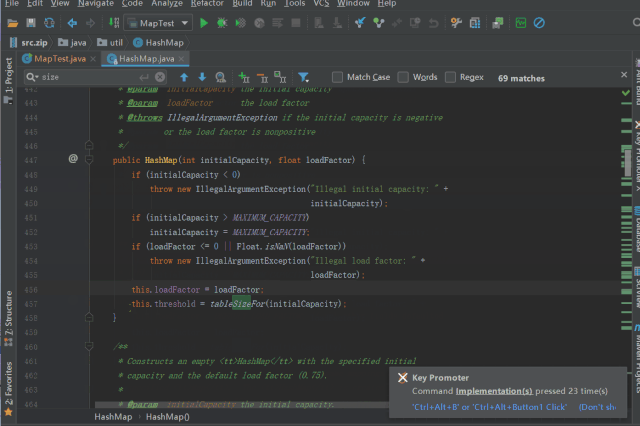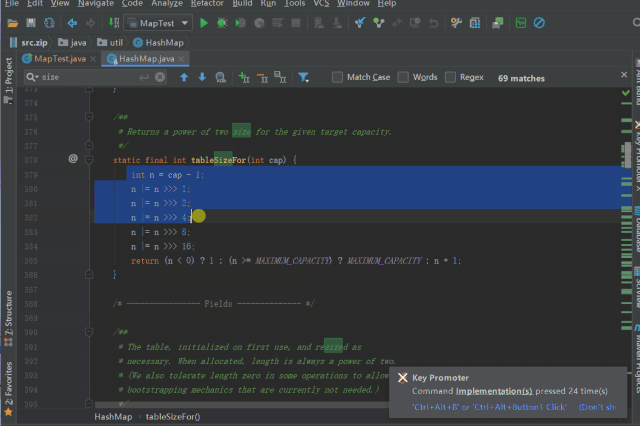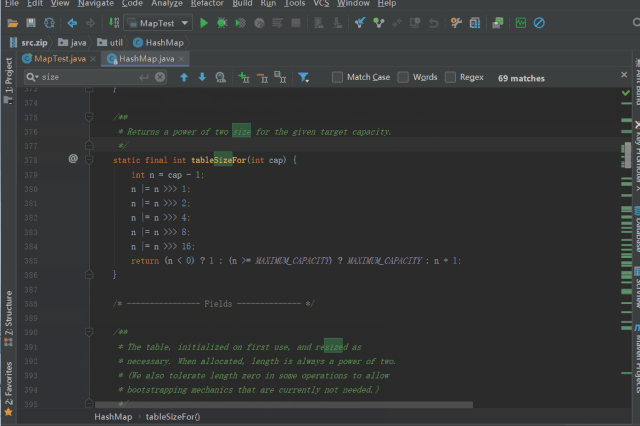
调用 tableSizeFor 进行 threshold 的初始化
/**
*Returnsapoweroftwosizeforthegiventargetcapacity.
*返回>=cap最小的2^n
*cap=10,则返回2^4=16;
*cap=5,则返回2^3=8;
*/
staticfinalinttableSizeFor(intcap){
intn=cap-1;
n|=n>>>1;
n|=n>>>2;
n|=n>>>4;
n|=n>>>8;
n|=n>>>16;
return(n<0)?1:(n>=MAXIMUM_CAPACITY)?MAXIMUM_CAPACITY:n+1;
}
虽然此处初始化的是 threshold,但后面初始化 table 的时候,会将其用于 table 的 length,同时会重置 threshold 为 table.length * loadFactor
自此,问题 5 也就清楚了
Map map = new HashMap(1000); 当我们存入多少个元素时会触发map的扩容
此时的 table.length = 2^10 = 1024; threshold = 1024 * 0.75 = 768; 所以存入第 769 个元素时进行扩容
Map map1 = new HashMap(10000); 我们存入第 10001个元素时会触发 map1 扩容吗
此时的 table.length = 2^14 = 16384; threshold = 16384 * 0.75 = 12288; 所以存入第 10001 个元素时不会进行扩容
问题6:加载因子
为什么加载因子的默认值是 0.75,并且不推荐我们修改
如果loadFactor太小,那么map中的table需要不断的扩容,扩容是个耗时的过程
如果loadFactor太大,那么map中table放满了也不不会扩容,导致冲突越来越多,解决冲突而起的链表越来越长,效率越来越低
而 0.75 这是一个折中的值,是一个比较理想的值
总结
1、table.length = 2^n,是为了能利用位运算(&)来求 key 的下标,而 h&(length-1) 是为了充分利用 table 的空间,并减少 key 的碰撞
2、加载因子太小, table 需要不断的扩容,影响 put 效率;太大会导致碰撞越来越多,链表越来越长(转红黑树),影响效率;0.75 是一个比较理想的中间值
3、table.length = 2^n、hash 方法获取 key 的 h、加载因子 0.75、数组 + 链表(或红黑树),一环扣一环,保证了 key 在 table 中的均匀分配,充分利用了空间,也保证了操作效率,环环相扣的,而不是心血来潮的随意处理;缺了一环,其他的环就无意义了!
4、网上有个 put 方法的流程图画的挺好,我就偷懒了
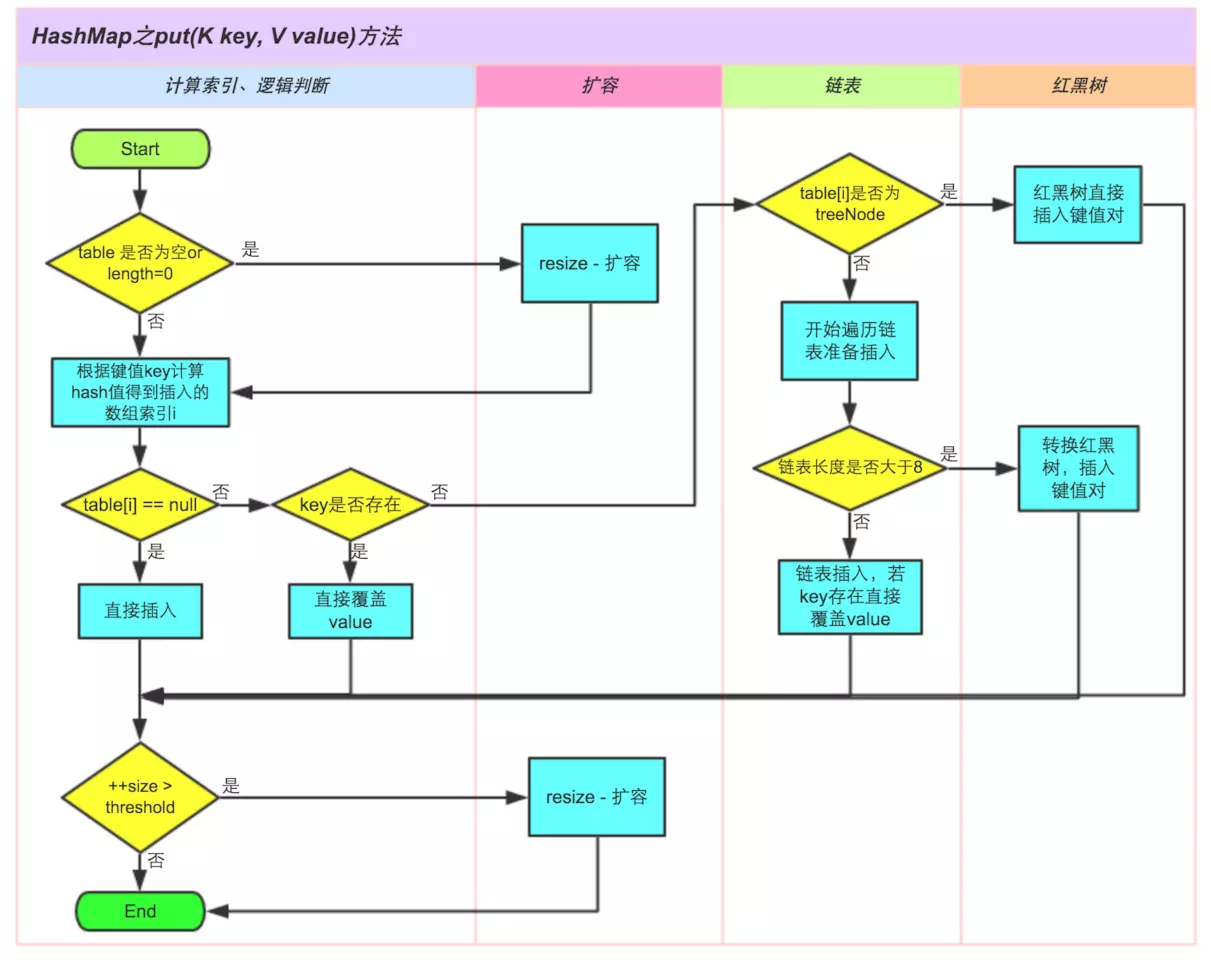
参考
java提高篇(二三)-----HashMap 【原创】HashMap复习精讲 面试官:"准备用HashMap存1w条数据,构造时传10000还会触发扩容吗?"
来源:cnblogs.com/youzhibing/p/11833040.html
推荐:
主流Java进阶技术(学习资料分享)


![[经典课程]打造扛得住的MySQL数据库架构](https://static.kouhao8.com/upload/top1sheji/190721/f20437dc4476c827ad96b0dcea28a4fd.jpg?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)




![[JAVA面试题] 传智博客Java就业班面试资料java面试题(程序猿面试技巧+常见笔试题分析) 六讲](https://static.kouhao8.com/sucaidashi/xkbb/78347caafea46f36a69b5d05ca66ad05.png?x-oss-process=image/format,webp/resize,w_88/crop,w_88,h_88,g_nw)



















相关资源